On March 12, 2024 between 15:23 UTC and 16:13 UTC, some HubSpot customers with data hosted in the USA were unable to log in to their accounts, access their content, and/or use our tools. Customers with data hosted in other regions were not impacted by this incident.
We apologize for any impact this incident may have had on you and your business. Reliability is a guiding value at HubSpot that we care about deeply. As such, we would like to take this opportunity to share with you what happened and what we're doing to help prevent similar issues from happening again.
On March 12, the flow of API requests to our server infrastructure were impaired by unusually high levels of traffic congestion. This congestion caused a portion of these requests to fail across a number of HubSpot workflows.
Architecture Overview
Managing the flow of this traffic is a core component to HubSpot's reliability strategy. Below, we show how your requests are routed to our server infrastructure today.
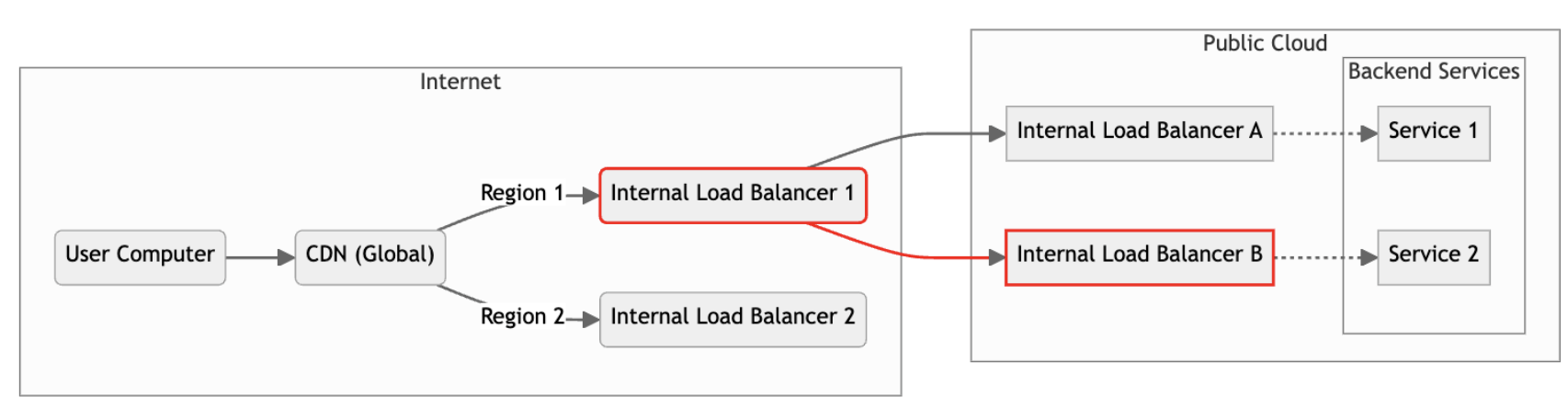 Simplified System Architecture Diagram
Simplified System Architecture Diagram
HubSpot partners with a content delivery network (CDN) provider. We use this CDN to receive traffic from your browser. A CDN allows us to serve your content requests more quickly and ensure your data stays local. We separate HubSpot customers into regions primarily for performance and governance reasons (FAQ). These regions are also intentionally isolated from one another for greater resilience. Because of these measures, the event on March 12 was isolated to only the North American region.
We locate our CDN presence as close to you geographically as we can and use it to route requests to the appropriate region of our main cloud provider, where our API services (aka backend servers) live. As part of the flow of your API requests across the internet, our cloud provider forwards requests to our regionally based, internal load balancers (a type of software service that distributes incoming requests to other services). HubSpot load balancers are based on an open-source project called Envoy.
Inside HubSpot's server infrastructure, the requests are routed to the correct backend service to fulfill your API request and return data for your browser to render. HubSpot’s scale and microservice architecture means we operate dozens of separate internal load balancers and thousands of different backend services to process the requests on your behalf.
The Incident
At HubSpot, we are constantly evaluating and improving our server infrastructure. Recently, one of our engineering teams identified a series of improvements to the management of network connections between our cloud and CDN partners. Throughout Q1 2024, they rolled out this change behind the scenes.
Let's switch to a timeline format for the events on March 12, 2024. All times are relative to the UTC timezone.
What We Learned
We conduct detailed post-incident reviews for all incidents to ensure that we have responded appropriately and proportionally to the situation. We use these reviews to identify opportunities to reduce the likelihood of similar events happening in the future and to apply learnings to our future product reliability efforts.
We are early in this process, but a few improvements have already been identified and implemented.
- We have tuned the memory and network connection limits of our internal load balancers to better route API requests while absorbing extreme spikes in connection load. These updates change when and how aggressively we scale our load balancers to meet demand. These refined constraints also mitigate the customer impact of future traffic spikes by triggering the scaling operation before we hit memory exhaustion conditions.
- A safeguard in our automation meant to prevent unbounded load balancer scaling operations slowed our response by 3-5 minutes. As every minute counts in an ongoing incident, we have implemented a quick software override to allow incident responders to circumvent normal scaling protections in emergency situations.
- During the event, we discovered that internal metrics traffic were being transmitted over the main API load balancer blending its load with customer traffic load even though we do not prioritize them equally. We have migrated the metrics traffic to its own dedicated load balancer to permanently reduce load on the main API load balancer and keep it focused on your traffic exclusively.
This event impacted a large number of people so we're committing to a number of longer term changes as well. Our first long-term commitment to you is to increase the transparency around widespread product outages. Going forward, our team will work to release a public retrospective for high severity incidents such as this one within approximately two weeks of the event.
In addition, we are implementing a number of longer term engineering programs internally. These are still in the roadmapping stages but should give you an idea of where we are headed as we dig deeper into the series of events.
- We will make a long-term investment into the observability of our traffic management and bring it up to par with other parts of our tech stack. This will improve our time-to-diagnose / time-to-recover in future incidents.
- We are auditing and refining our use of scheduled maintenance windows for potentially disruptive changes like this one and expanding the program to other systems that may also benefit from more explicit change management. This will minimize the impact to you by shifting the work to less critical times and a more transparent/predictable rhythm.
- We are kicking off a large project to revisit the isolation of API requests across our load balancers, similar to how we isolate customers across multiple regions. Increasing the isolation of API requests (like we are doing with the metrics request flow) will make it harder for non-critical or unrelated requests to destabilize the HubSpot application at the scale we saw on March 12.
Finally, we want to reiterate that reliability is a core tenet at HubSpot and reaffirm our promise to work diligently every day to ensure our customers have the tools they need to grow.