The Fault in Our JARs: Why We Stopped Building Fat JARs
HubSpot’s backend services are almost all written in Java. We have over 1,000 microservices constantly being built and deployed. When it comes time ...
Over the past few years, HubSpot has continued to rapidly grow its engineering team. We've seen corresponding growth in terms of lines of code, number of services, and volume of data. To help support this growth, we have a group of engineering teams called Platform Infrastructure. These teams are dedicated to making HubSpot engineers more efficient while also improving the security, reliability, and performance of our product. This includes focus areas like build and deploy, monitoring and alerting, and database operations.
Over time, Platform Infrastructure has grown to 90 engineers, spread across 24 teams. I work on one of these teams, called Backend as a Service, which is focused on improving our backend tech stack. This post will cover some of the tools, libraries, and frameworks our team has built in support of this mission.
For some context, pretty much all backend code at HubSpot is written in Java. Staying monoglot has allowed us to invest all of our resources into making our Java stack exceptional. It also means engineers can move teams or projects with less ramp-up time because everything uses the same tools, libraries, and frameworks. In addition, debugging and operational knowledge is transferable, which is an important skill set that can take a long time for an engineer to develop. This includes skills like interpreting a thread dump, navigating a heap dump, tuning the garbage collector, or debugging why one out of every thousand requests is slow. We may eventually need to go polyglot on the backend, but we think there are big advantages to staying monoglot as long as possible.
Our backend stack is comprised of different "primitives" that product teams can mix and match like Legos to build larger systems. These include things like REST APIs, Cron jobs, Kafka consumers, Hadoop jobs, Spark jobs, and more recently, gRPC and GraphQL APIs. Each of these primitives has corresponding code to integrate it into our stack. We've been working to centralize all of this code into a single repository called Bootstrap (not to be confused with the frontend toolkit).
So if you want to make a new REST API, you would add a dependency on bootstrap-rest, which provides a straightforward, fluent interface for defining your API. For example, here are a few lines of code that define a simple REST API:

This creates a production-ready REST API with monitoring, dashboards, alerting, etc. In addition, we try to ensure that each module in the Bootstrap repo has a corresponding testing module so that there is a clear way to write idiomatic tests. The net result is that the barrier to creating a new microservice is tiny.
As a companion to the Bootstrap repo, we have a repo called Connect, which aims to centralize client code for connecting to the various datastores we use. Within this repo, there is a separate module for each datastore. These libraries handle the basics like authentication and metrics, but are also expected to add guardrails and resiliency. This could include strategies like rejecting expensive queries before they hit the database, or using circuit breakers to fail fast when the database is having issues. In addition, as we learn new lessons during outage postmortems, we are able to apply these lessons to the Connect repo and every service at HubSpot benefits. Overall, we've found this pattern of standardization and centralization extremely beneficial.
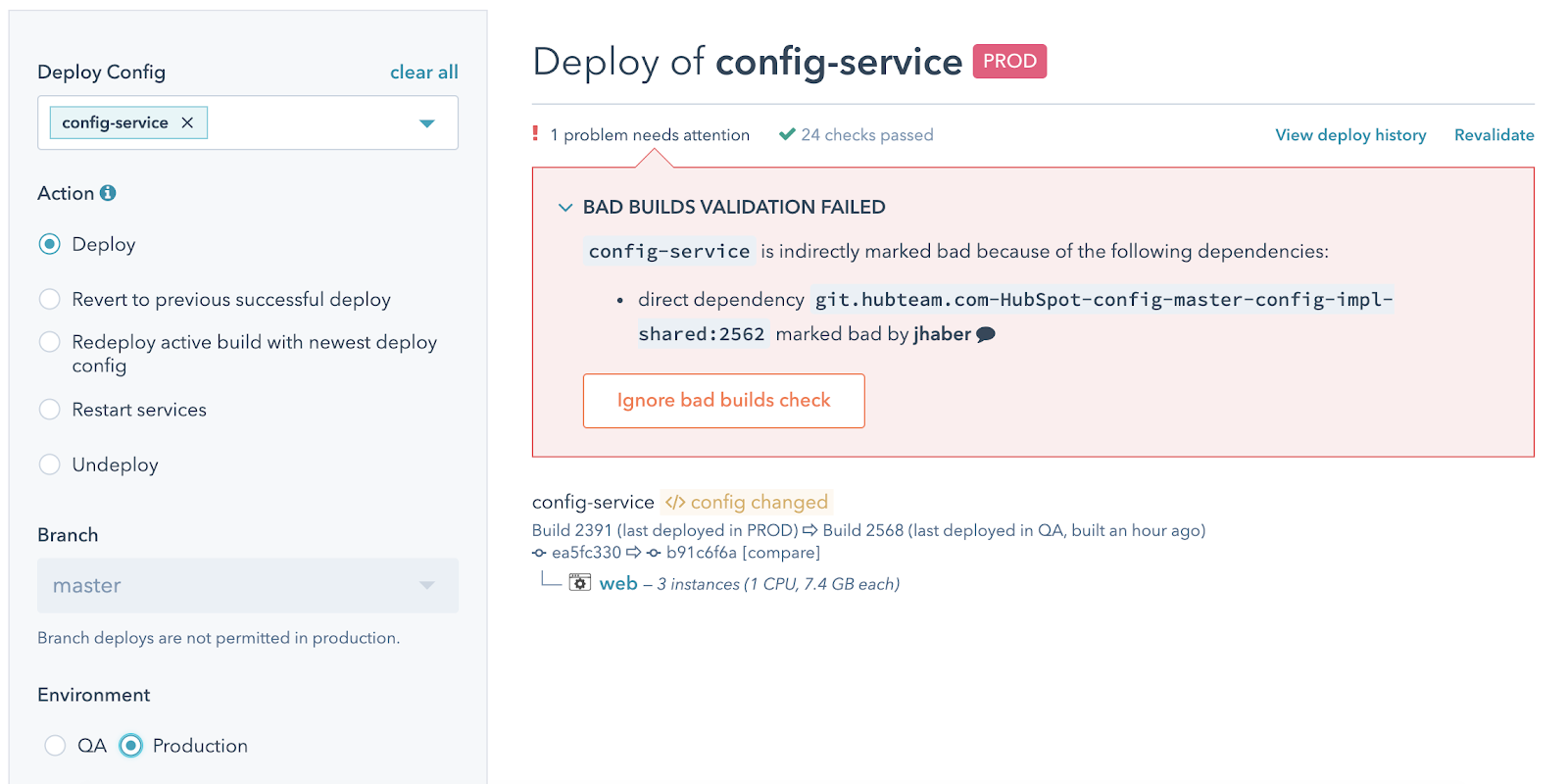
With so many services constantly being built and deployed, it's a challenge to keep track of what's currently deployed as well as what it depends on. To help manage this, we have an internal system called Overwatch. Overwatch stores metadata about all deployed services and their dependencies and lets you query against this data. You can ask questions like "which deployed services were built before timestamp X?" or "which deployed services depend on library Y version < Z?" Our build and deploy systems also integrate with Overwatch, which is a powerful integration that enables things like our "bad builds" feature. The way this works is that if you realize a particular commit in a library has a nasty bug, you can mark that build as "bad" in our build UI. Once you do that, our deploy system will prevent people from deploying anything that depends on the broken version of that library (and optionally notify teams via Slack if they've already deployed something using it).
We also often want to extract configuration values from our code and make them externally configurable. This could be something like the size of a thread pool, or the timeout on an HTTP request. We want to be able to change these values without needing to push a change to source control and wait for a rebuild. To handle these use cases, we built an internal configuration system called Config.
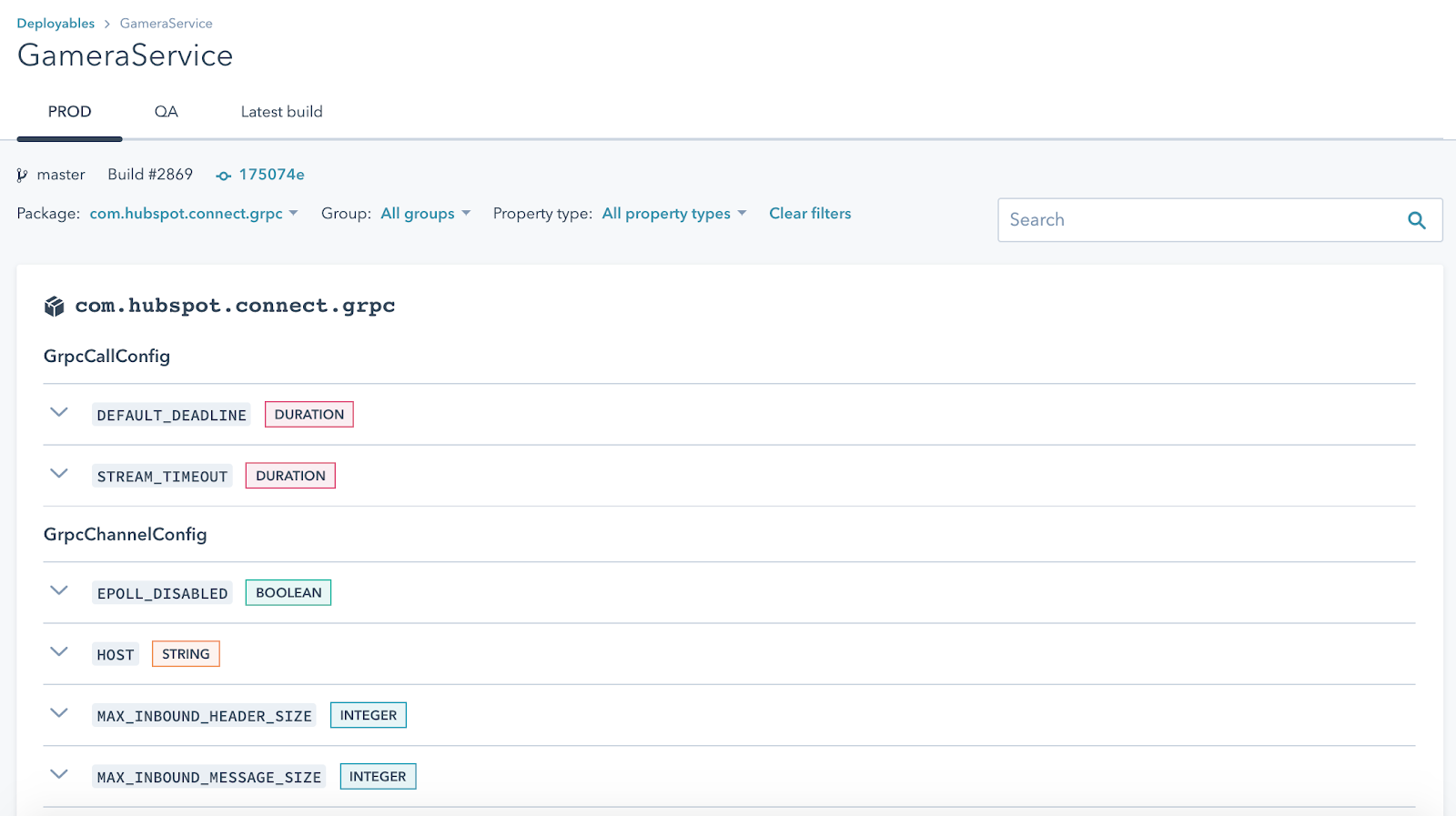
The Config workflow begins with developers defining their config options via an XML file that gets checked into their GitHub repo. We picked XML because it means that we get really good IDE support for code completion and validation simply by publishing an XSD. At build time, this config file will generate Java classes that you can use in your code to access the latest config values. This is convenient for users and also provides compile-time validation of the properties being accessed, which is a big improvement over our previous configuration system that required runtime lookups using magic strings. There is also a UI where you can create targeted overrides for any config option, which will take effect within a few seconds. And because the config options are typed, we can prevent invalid values from ever making it into the system. Additionally, because config options must be accessed via these generated Java classes, we can use the classpath to infer what config options are available to each service. This allows us to create a view in our Config UI that is customized to each service, showing only the config options that apply to it:
In addition to all of these existing tools, our team is working on some significant improvements to our backend stack. The biggest of these projects is the upgrade to Java 11, which has been a bit of a rollercoaster (looking at you, Spark). We're also investigating automated code formatting using prettier-java. Finally, we've integrated Error Prone into our build process and will begin leveraging it to catch, and automatically fix, problematic code patterns.