Lessons Learned from Last Week's S3 Outage
Like many companies, we were affected by last week's S3 outage. We were surprised, however, by the extent of the impact to our systems. It was a bit ...
Chaos testing at HubSpot came from the needs of our site reliability (SRE) team. We needed to test fault tolerance in the face of service to service call failures. Our main concern was upgrading our core databases from legacy MySQL to Vitess. We were skeptical about the failure mechanics of Vitess. We wanted to ensure they would be compatible with legacy MySQL mechanics. To test, we needed to inject failures into many calls between services in our stack.
Though we’ve previously undergone failure testing efforts, we recognized an opportunity to provide reusable tooling for future engineering efforts. Our SRE team could not intervene with every team that wanted to set up failure injection. We landed on the decision to write a custom java agent. Several HubSpot-specific environmental conditions led to this solution.
One quick point — one might well conclude that we could skip over the java agent route. Instead, we could include some code in our existing shared HTTP client implementation. We did consider this route but two things stopped us from proceeding further.
We will discuss several architectural choices made when implementing our failure injection framework. Specifically, we will cover:
Java agents provide a powerful API for intercepting class loading. They allow us to inject custom byte code into the JVM. Profiling applications, exporting metrics, and adding logging are typical use cases for java agents.
We used the ability to inject bytecode for two general use cases:
To store metadata we pull out variables passed to specific methods. We then store those values in the internal state of our failure injection library. To inject failures, we add code around the boundaries of all network calls. This added code in turn calls our failure handling logic. The handling logic reads the previously written state. It matches that state with failure configuration. The logic then determines what particular failure if any, to inject.
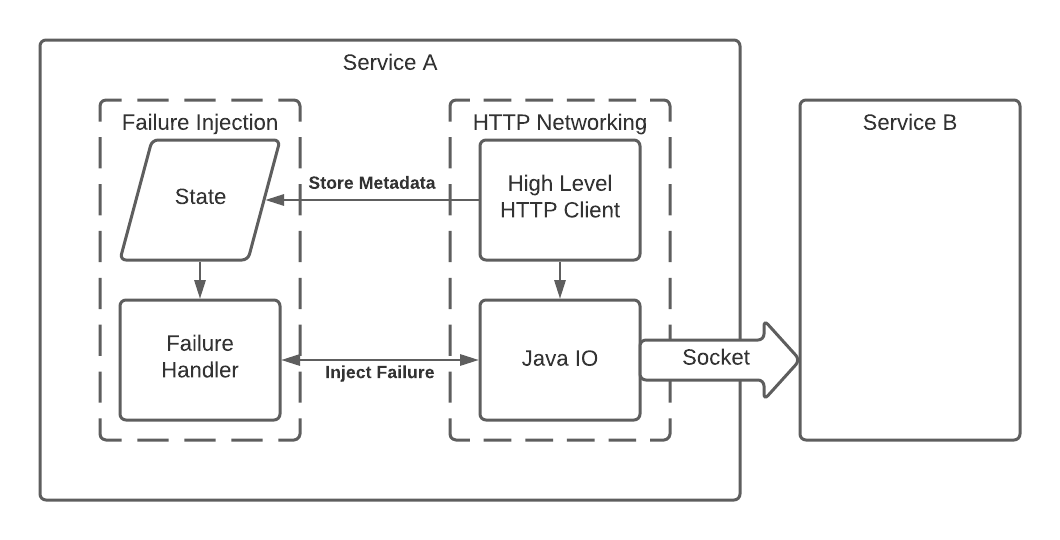
We chose to deploy our agent by packaging a jar and publishing via RPM. This allows our puppet code to manage versions and install the jar on all our machines opaquely. The size of the jar was incredibly important since all running services would load it. While we have tackled issues with large jars for application use cases, it is still a problem for our RPM artifacts. To help, we decided to additionally package a separate failure injection library. We then add this library as a runtime dependency of any service using the agent. Thus, the agent can rewrite byte-code by adding hooks that call out to static methods in the library. This strategy allows us to adequately balance concerns. We keep the agent's packaged jar size very small. The library, though, is still robust and well-tested. It contains the code to handle all the actual failure injection mechanics.
There are other more robust technologies for manipulating byte code — namely byte-buddy. We, however, chose to pursue the more lightweight javaassist library. It does not have the benefit of type safety, but it still provides a powerful API for injecting custom byte code. The type-free nature of javaassist means that we can limit our dependencies. In practice, our agent only depends on org.javaassist:javaassist. It has a total packaged jar size of roughly 32Kb.
We began by thinking about the mechanics of how failure injection would work in practice. There were a few considerations that would influence the final product. First, we needed to decide which failure types to support. Next, we had to consider the proper level of granularity on which to define failures. This included how exactly to specify targets in our configuration. Finally, we decided how we would allow users to update the failure configuration. We will explore the options we considered. We will also discuss how our choices influenced the final implementation.
When writing our failure injection agent, we began by enumerating scenarios to replicate. We started with the simplest failure event — a request flat out failing. The next ability we considered was adding latency to API calls. We soon realized that we also want to combine these two. A combination would look like added latency before eventually failing a call.
The final scenario we considered was a bit more subtle but very interesting. We had seen issues when POSTing to endpoints on a poorly behaving external service. Particularly, we considered the case where a client POSTs data to a service. Then, that service is slow to respond, causing our client to timeout its request. Finally, the service continues processing, eventually succeeding. We illustrate this series of events below.
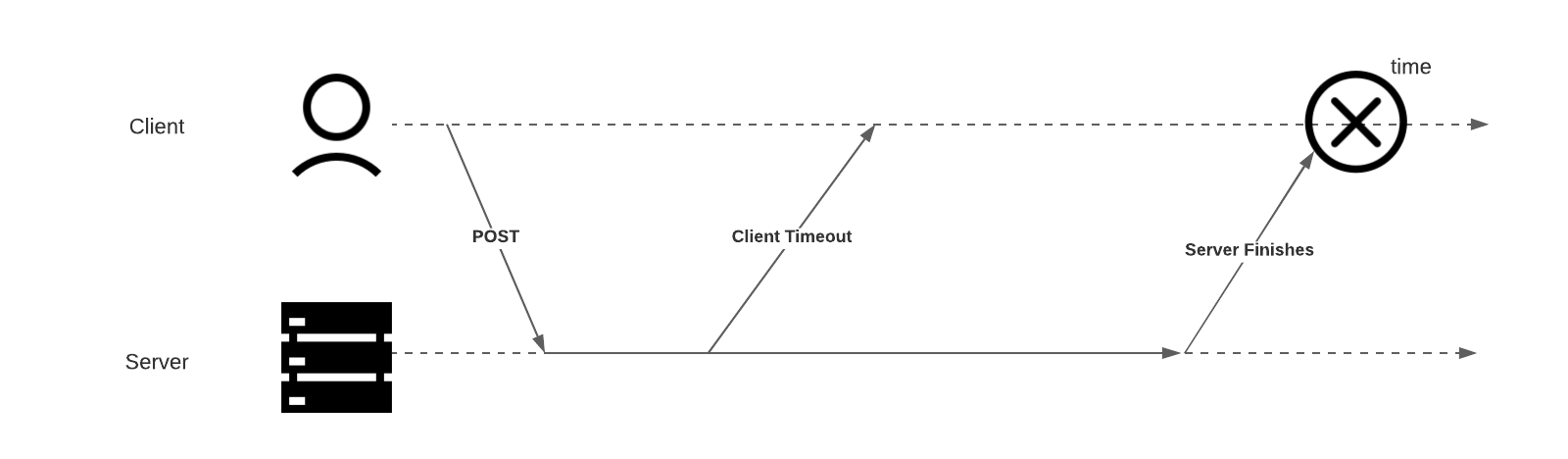
To simulate this scenario we needed a way to define where to inject failures or latency. The injection point itself needed to be configurable. We needed to place it either before or after making the request.
Our next consideration was what level of granularity we wanted to support. Our deployments run a given service as two different deployables — userweb instances that handle all user traffic and web instances that handle all internal API requests. This split lets us maintain low latency SLAs for our user-facing APIs. Our internal backend services call an entirely separate deployment. Each of these deployables runs many instances behind a common load balancer. This gave us the option of defining failures at a service level, a deployable level, or an instance level. We opted to support failures for deployables. This gives us a high level of granularity but simplifies configuration for users. It allows us to specify failures differently for user vs service-facing deployments. However, we can still do so in a human-readable format.
Finally, we needed to decide how exactly to update this configuration. Our general configuration model at HubSpot involves a tiered key-value store. Deployments read from the config store and apply matching values to populate config. They also poll to update values so that service reboots are not required. Generally, we apply new config values within minutes.
We discovered an issue with the longer latency (on the order of minutes) config updates. That failure injection config is not as useful for unit tests as it is for long-running services. To clear this hurdle, we added a second method of driving config. We allowed users to set failure injection values via code, storing values in memory. We could thus define the configuration for a single unit test. Afterward, we would clear the configuration following the test run.
These two approaches work well for scenarios following a common pattern:
The problem with this approach is limiting the scope of impact when running a live service. To target at a more specific level, we decided to support a similar configuration via a REST header. This choice allows us to set the failure conditions we want to see for a particular request. We can then issue the request and witness the response returned.
To handle any conflicts with config values, we process from the most to least specific values. We give first priority to headers that define config for a given request. The next priority is the dynamic in-memory value that defines it for a given instance. Finally, we process the configuration value defining failures for the entire deployable.
The java representation of our failure config looks like this:
Examples of the configuration representation in json:
We want to inject failures as close as possible to where we establish a socket to another service. This causes an interesting problem when reconciled with the actual code structure. Our HTTP client wrapper maintains the metadata about the service we are calling. By the time we are in the java networking code, we lose this context. At the socket level, we only have access to the literal InetAddress. We therefore introduce state management to manage this discontinuity. The state keeps metadata available to the actual failure handling code. Our java agent initiates this failure handling code in the low-level networking stack.
For state management, we rely on thread locals. Thread locals are a java wrapper type with special properties. Every time code accesses the variable, each thread will have its own copy. Essentially the wrapper stores a map of thread ID to value. It then sets and returns the value depending on the calling thread's ID. This construct is useful for maintaining thread-specific state — exactly what we need.
Example of thread locals in practice:
Thread locals run into problems when we use async HTTP clients. Async clients often put work onto a separate thread pool. We lose all our state we initially stored. Luckily, at HubSpot, we already solved this problem when implementing request tracing. For that use case, we need to supply and propagate a trace ID. Each request would get a unique ID and forward that value across any async boundaries. We manage this by implementing the interface ThreadContextFollower. This interface has methods for getting and setting thread context. Our in-house executor service factory implementations maintain a hook that invokes the interface. With the pattern already formalized, it was simple to solve our problem. We could create a new implementation of the ThreadContextFollower interface. This implementation is specific to the failure injection use case. It allows seamless transfer of all the state we need.
When we add up all these individual pieces we end up with a robust failure injection agent. Users can define failure config to add latency and/or fail requests. This failure can occur either before or after making those requests. Our java agent injects code that stores call context for external requests. We store this context in a ThreadLocal variable. Our ThreadContextFollower then forwards that state across async boundaries. When we start the socket connection, we call our failure handling code. The code matches the current state with the supplied failure injection config. If we find a match we introduce a failure depending on the particular configuration. The failure consists of either added latency, outright failure, or both. This architecture provides a full-featured failure injection agent. This agent allows HubSpot to begin with Chaos testing across our fleet of services.
Interested in working with a team that's just as invested in how you work as what you're working on? Check out our open positions and apply.