Lessons Learned from Last Week's S3 Outage
Like many companies, we were affected by last week's S3 outage. We were surprised, however, by the extent of the impact to our systems. It was a bit ...
An interesting task I undertook recently was hardening our memcached infrastructure. We're an SOA shop with hundreds of deployables, most of which will interact in some way with our memcached clusters. I thought I'd take the opportunity to break down the testing process into a basic tutorial that could be repurposed for other external resources.
Due to memcached's simple functionality and consistent performance, we are able to categorize failures into three categories as seen from the client drivers.
We are successful when the following are true for each of the above three conditions.
The real challenge with failure testing distributed resources is visibility, how can we get a clear view into what is actually happening. Picking the appropriate toolset ahead of time will ensure the job is done properly, picking the wrong tools will simply drag out the process until the proper tools are utilized or the testing is incomplete.
With tcpflow we can monitor packets going over the wire. With it we can watch in real time the (absense of) memcached traffic.
With jconsole we can watch the jvm for thread usage, memory growth and kick off GC.
With jmap we can count object instances should jconsole indicate memory issues.
With iptables we can simulate failed resources.
With a test application, watch and curl we can simulate steady traffic, say perhaps 1 request per memcached server per second. Be able to tail the output/access logs to watch for exceptions and the status of each request. The test appliction will also need custom endpoints that only contain simple get or set calls.
The following chalkboard sketch lays out the relationships between the various tools and components.
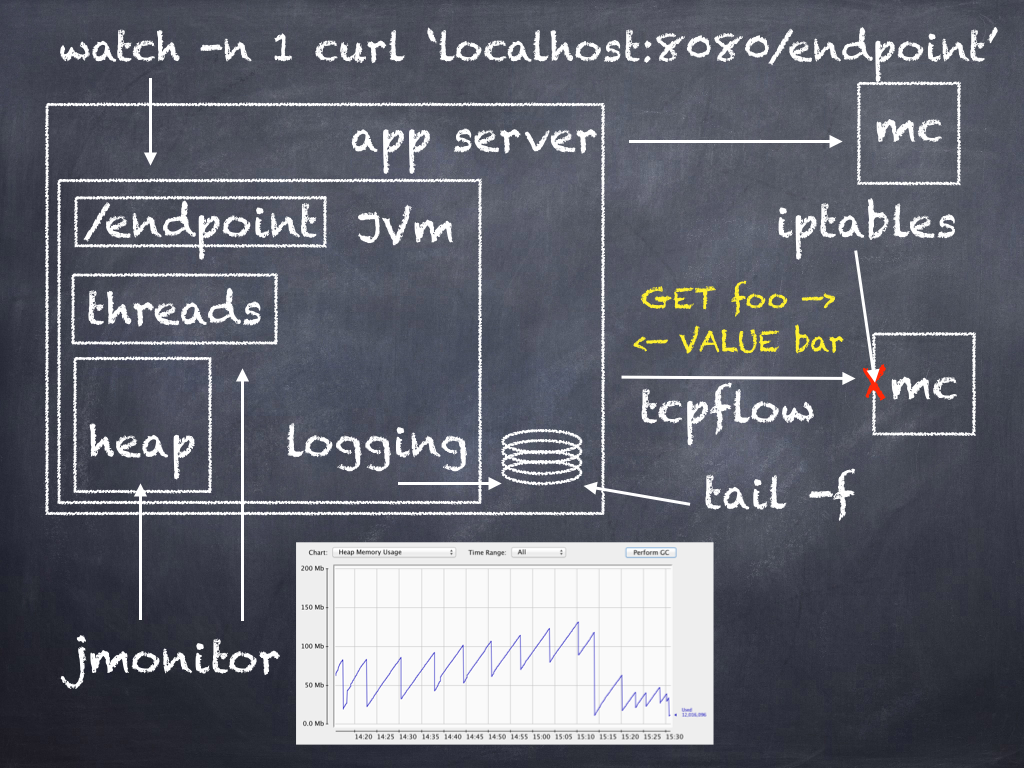
The testing environment for this blog was an internal example dropwizard application run locally on a laptop connecting to four memcached servers residing in AWS. Tcpflow and iptables will work fine in AWS and jconsole/jmap will function just fine on the laptop. The application server output all logs to stdout.
To maintain a constant flow of traffic to all four memcached servers we used the ConnectionObserver in spymemcached to execute a stats call to each memcached server each second. This allowed us to easily monitor what communication channels were functional via tcpflow. As necessary we also used watch with curl to simulate steady traffic to a specific test endpoint.
executor.scheduleAtFixedRate(new MemcachedKeepAliveRunnable(), 1000, 1000, TimeUnit.MILLISECONDS);
private class MemcachedKeepAliveRunnable implements Runnable {public void run() { memcachedClient.getStats(); }}
A custom endpoint was added to the app server to get and set a value in memcached. The value that is get/set each time helps us choose which memcached server to manipulate. We run tcpflow locally and use curl to hit the custom endpoint. Whichever memcached server is the target for the get/set operation becomes our guinea pig.
With a simple networking setup, finding the memcached server that serves traffic for the testing key is as simple as running tcpflow on the local server that the app server is running on. For other scenarios such as a mac laptop going over a vpn to the memcached servers, tcpflow will need to be run on each memcached server. Each captured packet/flow is identified by the source_ip.port-dest_id.port, on both sides of the connection. Ie the source-dest prefix will look the same on both the client and remote servers.
$ tcpflow -cv -i eth0 port 11211 | grep testing_keytcpflow[2806]: tcpflow version 0.21 by Jeremy Elson <jelson@circlemud.org>tcpflow[2806]: looking for handler for datalink type 1 for interface eth0tcpflow[2806]: found max FDs to be 16 using OPEN_MAXtcpflow[2806]: listening on eth0010.010.010.001.15422-192.168.001.200.11211: set testing_key 0 300 13 010.010.010.001.15422-192.168.001.200.11211: get testing_key192.168.001.200.11211-010.010.010.001.15422: VALUE testing_key 0 13
In this example the tcp packets for setting and getting the keys originated from 10.10.10.1 and were received on 192.168.1.200. The value being returned from the get operation was sent from server 192.168.1.200 and received on server 10.10.10.1. Whichever side of the connection is using port 11211 is the memcached server.
We've now identified our guinea pig memcached server. To test timeouts we need to simulate the memcached server taking a long time to respond. Never responding is a subset of "long time to respond", so to test we'll drop all packets via iptables. From the perspective of the memcached client drivers, we are going to allow packets to be passed to the local host's networking stack, but we'll drop them either on the local host or the remote host. Similar to the tcpflow tool, we can pick either side of the network connection to manipulate.
# Drop packets on the memcached server
iptables -A INPUT -p tcp --dport 11211 -d 192.168.1.200 -j DROP
# Drop packets on the client server
iptables -A OUTPUT -p tcp --dport 11211 -d 192.168.1.200 -j DROP
# To flush all iptables rules
iptables -F
Lets verify iptables is indeed interrupting traffic. With the constant stream of stats pings every one second ongoing, run the iptables command and start dropping packets. The flow of responses to the stats calls on the guinea pig server should have stopped while traffic to the other memcached servers continues uninterrupted. Be aware that there may already be rules in place, and running the specified command will add the rule to the end of the chain where it would probably be ineffective. If thats the case you'll need to flush the rules and/or add yours in the appropriate location for the duration of the testing.
For the first test we'll verify the configured 1s timeout works as designed.
Running the specified steps results in spymemcached exceptions like the following.
! net.spy.memcached.OperationTimeoutException: Timeout waiting for value
! at net.spy.memcached.MemcachedClient.get(MemcachedClient.java:1185) ~[ExampleDropWizardService-2.0-SNAPSHOT.jar:na]
! at net.spy.memcached.MemcachedClient.get(MemcachedClient.java:1200) ~[ExampleDropWizardService-2.0-SNAPSHOT.jar:na]
! at com.hubspot.dropwizard.example.resources.AwesomeResource.get(AwesomeResource.java:50) ~[ExampleDropWizardService-2.0-SNAPSHOT.jar:na]
...
Caused by: ! net.spy.memcached.internal.CheckedOperationTimeoutException: Timed out waiting for operation - failing node: guineapig.memcached.net/192.168.1.200:11211
! at net.spy.memcached.internal.OperationFuture.get(OperationFuture.java:73) ~[ExampleDropWizardService-2.0-SNAPSHOT.jar:na]
! at net.spy.memcached.internal.GetFuture.get(GetFuture.java:38) ~[ExampleDropWizardService-2.0-SNAPSHOT.jar:na]
! at net.spy.memcached.MemcachedClient.get(MemcachedClient.java:1178) ~[ExampleDropWizardService-2.0-SNAPSHOT.jar:na]
!... 59 common frames omitted
The length of time until timeout isn't specified in the stack trace, it was collected explicitly in our code to determine the configured 1s timeout was being honored.
long time = System.currentTimeMillis();try { memcachedClientIF.get("testing_key"); }catch (Exception e) { }System.out.println("Memcached.get time: "+ (System.currentTimeMillis() - time) +"ms");
Will the application server start up correctly if a memcached server is unavailable? There are a couple different ways we could envision this test failing. If the memcached drivers threw exceptions while being initialized due to lack of connectivity that could break the app server. In addition, an exception could be thrown while pre-initializing values from memcached. This second case is application logic dependent and thus will need to be verified on each application stack (ouch).
This test should be repeated for each memcached server verifying there isn't a single key used during startup that isn't handled properly on failure.
Repeating the test by dropping packets instead of rejecting them reveals interesting behavior. Again recall that our application constantly pings all memcached servers for stats every second as visible heartbeat for us to monitor. When packets are rejected by the memcached server, the drivers immediately ascertain the memcached server is unavailable and change the internal state accordingly. However if the packets are dropped instead, there is a 60s+ period until the remote memcached server is considererd down and a reconnection is queued.
Another interesting result appeared as we constantly hit the custom endpoint after starting the application server with packets being dropped. Before the remote memcached was marked as down, each custom endpoint call timed out at 1s as expected. However, after being marked down each hit to the custom endpoint also timed out after 1s instead of failing fast. Let's test this functionality a little more rigorously as our next test.
Do requests to a downed memcached server fail fast? In particular we are concerned with cases when memcached is a black hole, we don't want 1s timeouts for all calls for the 20min it takes to replace a memcached server. For example, here's a heatmap of a service showing a large portion of requests taking slightly over 1s for a 10min+ period. The period corrosponds with a single memcached server rebooting.

Failure. The memcached.get() calls all timeout instead of failing fast. Digging through the spymemcached docs and code it appears the failure mode we have set is FailureMode.Retry which will force a retry even when a memcached server is down. Let's change Retry to Cancel and test again.
On Step 6 this second time around with FailureMode.Cancel, the custom endpoint stops timing out and fails fast after the memcached server has been marked down.
Now we'll test if there is a thread leak during longer outages. Spymemcached client drivers keep one open connection to each remote memcached server. Requests are sent individually over the wire and are grouped/optimized if possible. Therefore under the hood all requests are inherently asynchronous and spymemcached spins up and handles its own threads as it sees fit. To test for thread leaks we'll need to keep constant traffic, then sever a connection to a remote memcached server, then reconnect, then sever for several iterations. After that we can leave a connection severed for awhile.
To monitor thread usage during the test we'll use jconsole.
The testing we did for this step is probably a bit outside the bounds of what would normally happen. It's not very likely a memcached server would disappear/appear many times, though those actions are the most likely to be the cause of a leak of some kind. One of the more likely scenarios we'll see in the wild is a memcached server being unavailable for 15-30min as a replacement is being spun up.
Our testing showed no thread leaks, the thread count stayed constant throughout the testing.

Testing for memory leaks will follow the same testing routine as the testing for thread leaks with the additional help from jmap. Spoiler alert, there is a memory leak, and it was confirmed via jmap. Jmap can provide us with counts of objects inside the jvm. Excecuting the jmap command multiple times sequentially shows us which objects continue to collect. There are lots of objects, we can use an educated guess (and some hindsight) to just look for objects with memcache in their package structure. There's a pretty long tail for classes with only one instance, no point in examining those when looking for object leaks (grep -v).
jmap -histo <pid> | grep -E 'Latch|memcache' | grep -v " 1 "
The two signs of a memory leak will be the overall heap size in jconsole and the comparison of objects between jmap calls. To be most accurate, both of those should only be measured right after jvm garbage collection.
Repeated iterations of a remote memcached server being down did not result in an overall trend indicative of a memory leak. A remote memcached server being down for a long period of time however does appear to have a memory leak as shown in the following char. Starting a bit before 2:20 until around 3:14 we see an upward trend of memory usage. The drops in memory usage came the next GC after re-enabling the packet flow to the remote memcached server. The cycle is repeated a second time as the packet flow is disrupted around 3:15 until 3:31.

During the testing we were able to track objects being collected with jmap. Here are some sample objects collected while the remote memcached server was unavailable. jmap was run right after GC was triggered to ensure the most accurate results.
num #instances #bytes class name
----------------------------------------------
53: 512 36864 net.spy.memcached.protocol.ascii.StatsOperationImpl
82: 445 14240 java.util.concurrent.CountDownLatch$Sync
91: 512 12288 net.spy.memcached.MemcachedClient$11$1
97: 440 10560 net.spy.memcached.MemcachedClient$11
125: 445 7120 java.util.concurrent.CountDownLatchNow here's the same set of objects a couple minutes later, again run directly after GC was triggered.
num #instances #bytes class name
----------------------------------------------
36: 1256 90432 net.spy.memcached.protocol.ascii.StatsOperationImpl
78: 1256 30144 net.spy.memcached.MemcachedClient$11$1
91: 736 23552 java.util.concurrent.CountDownLatch$Sync
104: 731 17544 net.spy.memcached.MemcachedClient$11
132: 736 11776 java.util.concurrent.CountDownLatch
The jconsole graph shows a leak and the jmap data narrows it down to specific spymemcached objects.
Not coincidentally the solution to this problem is the same for fail fast, changing FailureMode.Retry to FailureMode.Cancel.
We've already confirmed that servers are eventually marked as down and after that requests will fail fast. Next we need to determine what that threshold is and if possible how to lengthen or shorten that time. One would expect this value to be configurable, so we'll start guessing at configuration fields and tune them up and down to see which has an effect.
After fiddling with a few params and reading through lots of code we were unable to find any lever that would shorten/lengthen the amount of time it takes the spymemcached drivers to notice the remote memcached server has disappeared inside our test environment. If you've got some understanding or insight into the spymemcached drivers and how servers get marked down please let us know in the comments!
Hopefully you'll agree with me that failure testing is easy once you get a feel for the proper tools. Iptables does an excellent job of quickly and easily simulating a memcached outage while tcpflow allows explicit verification of what is and what is not going over the wire.
For us the change from FailureMode.Retry to FailureMode.Cancel will help limit the disruption a failed memcached server can cause by allowing fail fast behavior.
For next steps we'll be trying these tests out in our qa and production environments, getting us closer to being best buds with Chaos Monkey.
