Our Journey to Multi-Region: Supporting Cross-Region Kafka Messaging
This is the last installment of a five-part series about HubSpot’s year-long project to rework our platform for multi-region support. Check out the ...
This is the second installment of a five-part series about HubSpot’s year-long project to rework our platform for multi-region support. Check out the introduction to the series here.
In this post, we will explore HubSpot’s strategy for adding multi-region support to incoming API calls. For some background, we expose a public API so that external developers can integrate with, or build on top of, the HubSpot platform. This public API is hosted on api.hubapi.com (you can find more details here). Requests are authenticated using either OAuth or a HubSpot API key (hapikey for short). As we started to plan the multi-region project, it became clear that this sort of global domain would be a challenge. For US customers, API calls should go straight to our US data center. Similarly for EU customers, API calls should go straight to our EU data center.
Theoretically, an easy solution would have been to split api.hubapi.com into api-na1.hubapi.com and api-eu1.hubapi.com. This would solve the problem on our end, as each domain could trivially route traffic to the correct Hublet. However, it would push the problem onto our external developers, who would have to update their code to use one of these new domains (based on where each HubSpot customer is hosted). This approach would effectively break all existing code written against HubSpot's public API.
Any solution which required external developers to update their code would take a very long time to roll out - and it would be a big project in its own right, with its own risks and challenges. One of the things we learned throughout this project is the value of detangling. It was very tempting to say "if we just change X, then challenge Y goes away or becomes much simpler". But if we went down that path, then completing the project would become dependent on a tangled web of tangentially related projects. Pretty quickly, we’d end up in a constant state of yak shaving. And any delay or setback in one of these related projects would likely jeopardize the timeline or success of the overall project. 
Sometimes tangling is the right way to go, but we wanted to exhaust all other options before going that route. In this case, it was clear that we should detangle these initiatives. We could design a new, Hublet-ized way to interact with our public APIs, but that shouldn't be a prerequisite for launching the EU Hublet. To unblock the launch, we needed to find a way to route API calls that worked transparently with all existing 3rd party code.
Solution
One approach is to route all API calls to a central routing service, hosted in the US, for example. This service could inspect the request, figure out which Hublet it should get routed to, and forward it there.
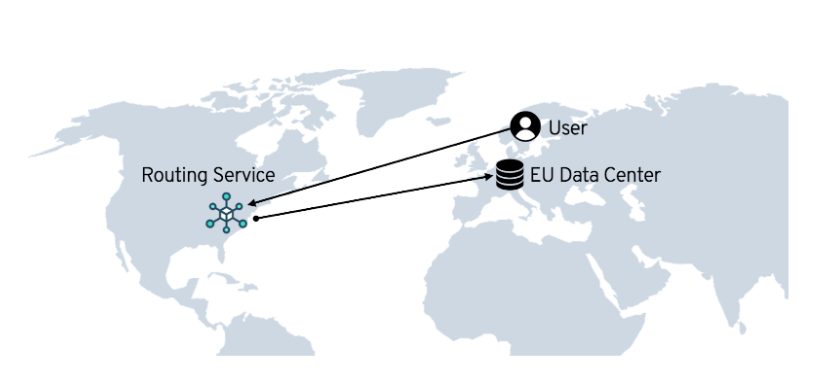
This would've worked from a functional perspective, but it failed to deliver on the project goals (outlined here). In particular, this solution would hurt performance, reliability, and data localization. From a performance perspective, imagine a HubSpot user in Sweden, hosted on our EU data center. If they made an API call, this should get routed directly to the EU Hublet in Germany. However, with a central routing service, the API call would travel to the US and then back to the EU, resulting in hundreds of milliseconds of unnecessary latency. Hosting the central routing service in the EU wouldn't solve this problem; it would have created the opposite problem, where API calls from the US would become slow. From a reliability perspective, this central routing service would've been a global point of failure, which is exactly what we were trying to avoid. And from a data localization perspective, we wanted to be able to tell our EU customers that their data is processed and stored in the EU. We can't do that if all of their API calls (many of which contain PII) were routed through the US.
At first glance this looked like a very tricky problem. We needed to take API calls coming in on a global domain and route them to the correct Hublet without sacrificing performance, reliability, or data localization. One option was to still use a routing service, but to run copies of it all around the world, using something like GeoDNS to automatically route calls to the nearest instance. This seemed promising, but it was pretty complicated and sounded a lot like a CDN. At HubSpot, we use Cloudflare as our CDN, and all incoming API calls already flow through it (in order to apply DDoS protection and WAF rules). Around this time we were starting to use Cloudflare Workers to power other parts of the HubSpot product. This is a really exciting technology that allows you to run code directly in Cloudflare's edge data centers.
If we could implement our routing service as a Cloudflare Worker, then it would be like having a distributed routing service running in all of Cloudflare's 250+ data centers around the world. This seemed like a good approach, so we decided to do a proof of concept. The idea was to turn api.hubapi.com into a thin facade backed by a Cloudflare Worker. This worker would decide whether each request should go to api-na1.hubapi.com or api-eu1.hubapi.com and forward it there. To minimize the performance and reliability risk, we wanted the worker to be able to make these routing decisions without any network calls, solely based on the request data itself. To make this possible, we decided to embed Hublet information directly into our API keys and OAuth tokens. Any existing tokens that predate this change were assumed to belong to the na1 Hublet. The pseudo code for the worker looked like this:
We rolled this out to QA for testing and it worked great. Using this approach, based on Cloudflare Workers, we were able to route API calls directly at the edge, without harming performance or reliability. If that same Swedish user made an API call, it would get routed to a Cloudflare data center in Sweden, and then straight to HubSpot's EU data center in Germany. After testing extensively in QA, we rolled this out in Production. For more than a year, all API calls to api.hubapi.com have been flowing through this codepath.
Learnings and future improvements
Overall we've been very happy with our solution using Cloudflare Workers. There are definitely pain points around local testing and observability, but we've been discussing these issues with Cloudflare and they're investing a lot in the Workers developer experience.
One implementation issue we ran into is that, at first, our Worker was changing the URL when firing the subrequest. When testing, we ran into issues with some of our endpoints that use signature validation. It turns out that the client was computing a signature based on api.hubapi.com. But when the request reached our API after passing through the Worker, the Host header had changed to api-na1.hubapi.com, which invalidated the signature. The fix was to use the special resolveOverride directive, which allows you to forward a request without changing the Host header.
Looking forward, we still want to get traffic off of api.hubapi.com and onto more granular domains. This will allow us to use tools such as Cloudflare Regional Services and Cloudflare Geo Key Manager in order to provide even stronger data localization guarantees to our customers.
Stay tuned for our next post in this series, explaining the system we built to ensure that our MySQL auto-increment IDs are globally unique.
Other multi-region blog posts:
These are the types of challenges we solve for on a daily basis at HubSpot. If projects like this sound exciting to you, we’re hiring! Check out our open positions and apply.