Looking Back: Our Most Popular Posts of 2023
2023 was an incredible year of growth for us at HubSpot directly driven by our Product and Engineering teams who tackled hard problems that helped ...
After noting how a single hardware failure could domino into high-severity database outages, HubSpot engineers used constraint solving to build a system that balances MySQL workloads across hundreds of clusters and thousands of machines.
HubSpot has a large Vitess and MySQL footprint: today we have over 750 Vitess shards per datacenter (one in the US, and one in the EU), where each shard is a 3-instance MySQL cluster. In total, Vitess handles just about 1 million queries per second steady-state.
All of Vitess, and therefore all of our MySQL clusters, run inside Kubernetes. Operating in Kubernetes has been a big boon for our data infrastructure teams, helping to commodify many core pieces of infrastructure we had previously rolled ourselves.
But of course, no system comes without compromises: with our installation on Kubernetes, we run many Vitess/MySQL instances on the same nodes, and therefore the same physical machines. While very cost effective, this can create some tricky failure scenarios. For example, a hardware failure on a single Kubernetes node can trigger failovers across several, sometimes ten or more (!), MySQL clusters all at once.
Given the inevitability of hardware failures, our data infra teams are working to react and recover from failures more quickly and transparently, and are exploring ways to preemptively reduce the impact radius of failures before they happen.
In this post, we’ll explore a system our SQL team built to minimize the impact of hardware failures by balancing our primary/replica assignments across nodes and availability zones. We will call this system the Vitess Balancer.
The Primary Problem: Concentrated Risk
Understanding the impact of hardware failures on our MySQL clusters requires understanding a bit of our cluster topology.
Each MySQL cluster has 3 instances, with a replication setup that designates 1 instance as the primary, and the other 2 as replicas. The primary/replica assignment of which instances are mapped to which roles is managed by the Vitess control plane, and a reparent operation can be used to swap primary and replica roles between instances.
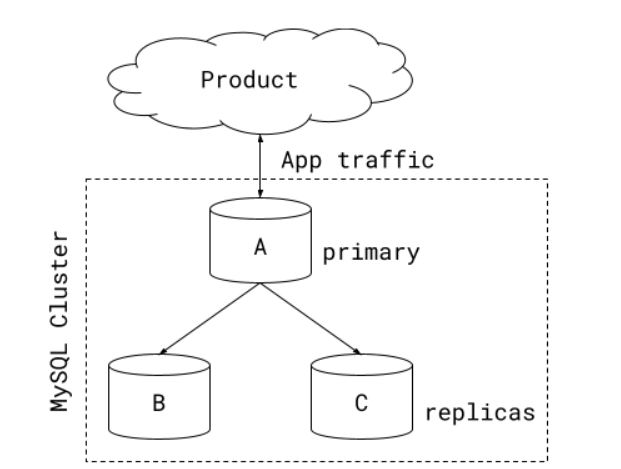
Figure 1: MySQL cluster topology. A standard MySQL cluster, with one primary and two replicas. All application traffic flows through the primary.
All of a cluster’s traffic, both reads and writes, always flows through the cluster’s primary. While we do not use replicas to serve traffic, they are available to help make data durable through MySQL’s semisync replication. We also reparent to replicas, turning a replica into the primary, during failovers or rolling restarts.
As a result of their varied workloads, primaries and replicas have very different failure modes.
Since all traffic is served through the primary, an outage that affects the primary needs immediate recovery! If our automation does not immediately failover and promote one of the replicas to serve as the new primary, some portion of the HubSpot product, and therefore our customer experience, will be visibly impacted.
Comparatively, an outage that affects a replica should go unnoticed by the customer. While the instance is being recovered, the cluster’s fault tolerance will be reduced, but unless an additional failure occurs, there will be no customer impact.
Our conclusion is then: losing a primary is much more precarious than losing a replica!
Let’s see how the primary/replica assignments play out when mapped onto a larger deployment.
Thanks to the Kubernetes scheduler, we have a fairly even distribution of our MySQL clusters across all of the available nodes. And each cluster consists of a StatefulSet definition, which Kubernetes automatically spreads across availability zones.
An example 4-cluster deployment might then look like the following:
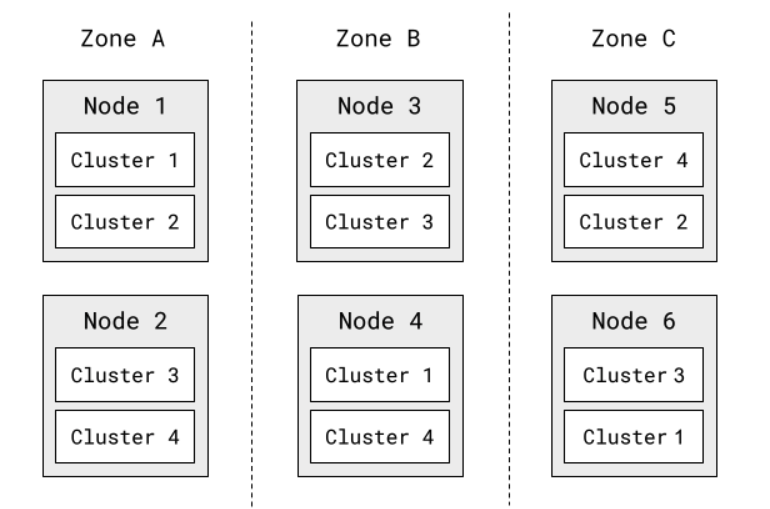
Figure 2: Example deployment of 4 MySQL clusters. Clusters are distributed across 3 availability zones and 6 Kubernetes nodes.
Each MySQL cluster has three instances, with one instance per availability zone. Each Kubernetes node has the same number of MySQL instances. Each availability zone has the same number of MySQL instances. At a glance, this deployment looks nice and evenly distributed.
However, this isn’t yet a complete view. While our physical distribution of MySQL instances looks good, our primary/replica assignments could continue to be unevenly distributed or skewed to specific nodes or availability zones. This skew can lead to situations where certain nodes or availability zones are overweighted with primaries, which concentrates risk because, as we just learned, losing a primary is much worse than losing a replica!
As an example, here’s a scenario where the same workload has every primary packed on to just two nodes, and all inside the same availability zone: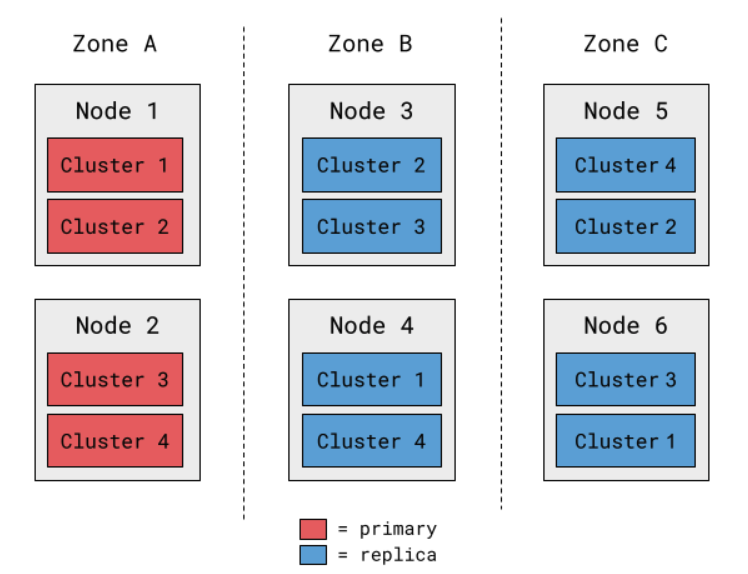
Figure 3: Example of poor primary/replica distribution in a 4-cluster deployment.
This type of skew leaves us vulnerable to high-severity failures. If Zone A had an issue, every one of our clusters would need recovery! So many clusters failing at once will likely impair a broad set of product functionality, and in the worst case, where the impairment slips past our recovery automation, it can extend total downtime and spread our on-call engineers thin as they work to manually resolve each issue.
It would be preferable to assign primaries so that a node or availability zone outage always has a smaller, more evenly-distributed impact radius:
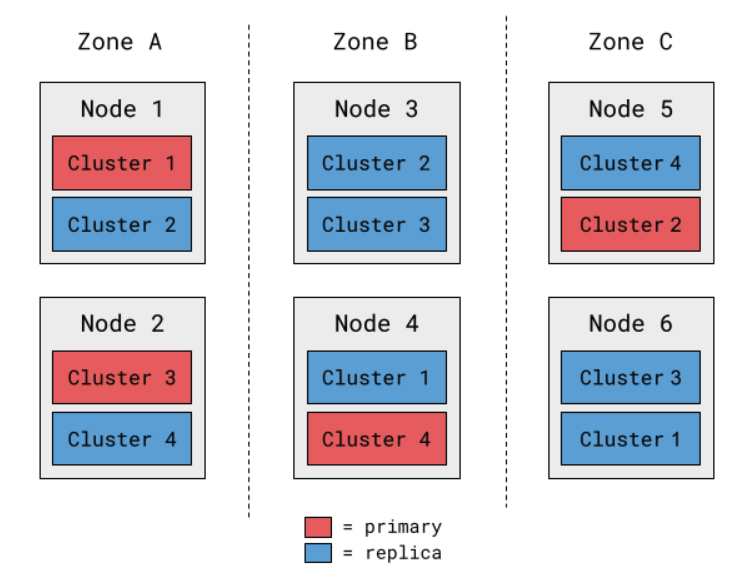
Figure 4: Example of well-balanced primary/replica distribution in a 4-cluster deployment.
In this scenario, we have the same physical layout as before, but by flipping just a few primary/replica assignments, we’ve halved the worst-case outcomes of losing a node or availability zone. Even if we were to encounter a novel impairment that requires manual intervention, it will have smaller product impact and fewer failures to resolve.
Knowing that we could meaningfully improve reliability just by flipping primary/replica assignments, our data infra SQL team set out to build a system to do so. We used a constraint solver to build a model that computes a plan to evenly distribute primary/replica assignments, and we extended our Vitess operator to be able to execute those plans. Together, the model and the operator encompass what we have dubbed the Vitess Balancer.
Balancer Part 1: The Model
To minimize the chance of the high-severity failures we outlined above, we started with two core goals:
For the implementation, we reached for OR-Tools, a fantastic optimizations library built by Google. Our data infra teams had previous experience using OR-Tools to evenly balance Kafka partition assignments across brokers, so using it to balance MySQL primary assignments seemed like a good fit.
Modeling problems on top of a constraint solver can be a bit mind-bending at first. It requires expressing a problem in terms of variables and constraints over those variables. At the end, if a solution is feasible, the solver spits out values for those variables that satisfy all the constraints.
To please the solver, we first needed to rephrase our goals in terms of specific numbers we could ask OR-Tools to minimize or maximize. This requirement led us to the revised goals of:
We then needed to figure out what our core variables were going to be. In our case, we wanted to figure out which MySQL instances should be primaries and which should be replicas. For each MySQL instance, we then created an integer variable that could be either 0 or 1. We used 0 to represent a replica assignment and 1 to represent a primary assignment:
In order to get valid solutions from the solver, there were two crucial invariants we needed to teach our model. First, every cluster must have a primary. Second, a cluster may only have one primary at a time. We can express both of these constraints together, by telling the model that the sum of each instance variable in a cluster must be 1:
Now when the solver is running, it will throw out any solutions that did not assign a primary to a cluster (variables summed to 0), or assigned more than one primary (variables summed >1). Neat!
We then wanted to add in variables to track how many primaries are assigned to each Kubernetes node. This step wasn’t too bad: When we’re building our initial instance variables, we can additionally group them based on their Kubernetes node:
Then, for each Kubernetes node, we create a new variable equal to the number of primaries it has:
We now have variables that represent how many primaries are assigned to each Kubernetes node. We can then create a variable equal to the max of those variables, to represent the maximum number of primaries assigned to any one Kubernetes node:
Finally, we can add in a goal that instructs the model to minimize this latest variable:
This final step gets us to our initial stated goal, which was to minimize the maximum number of primaries per node.
Coooool — our model for evenly distributing primaries across Kubernetes nodes is done! When we punch the model into the solver, OR-Tools will spit back out variable assignments telling us which MySQL instances should be primaries (those with value 1) and which should be replicas (those with value 0). The solver will have explored the space until it concludes with an optimal solution to minimize the max number of primaries on a given node. In practice, the solution space isn’t huge and OR-Tools is able to find a solution in a few seconds.
Adding in the constraint to balance primaries across availability zones is virtually identical to balancing across nodes, with initial groupings by zone rather than node, so we won’t cover the code here.
In simulation, the plans our model generated were very promising. We’ll get to the numbers soon, but we saw huge improvements in our overall distribution. And as our model developed, we had more and more ideas for new rules to add in, including the following goals:
Balancer Part 2: The Operator
With our model in place, we now needed a way to actually execute the plans that OR-Tools generated. We created a new Kubernetes custom resource definition, the OperatorAction, as a generic wrapper around asynchronous operations we want to apply to our Vitess cluster. We then extended our Vitess operator to watch for and execute OperatorActions.
We next created a daemon loaded up with our OR-Tools model that periodically recomputes a new primary/replica assignment plan. The daemon transforms the final primary/replica assignment variables into an OperatorAction custom resource with the full list of clusters that need to be reparented. We give ourselves visibility into the plans the daemon is creating by having it drop a message in Slack each time it computes a plan that differs from the current state of the world.
Our Vitess operator watches for OperatorActions, choosing whether or not to execute them as they come in based on the current state and health of the Vitess cluster and individual MySQL clusters. If the operator is idle and everything is healthy, the operator will execute reparent operations until the plan is complete. If the operator is already busy, the cluster is unhealthy, or the plan is out of date, the operator will discard the plan and wait for a new one to be recalculated.
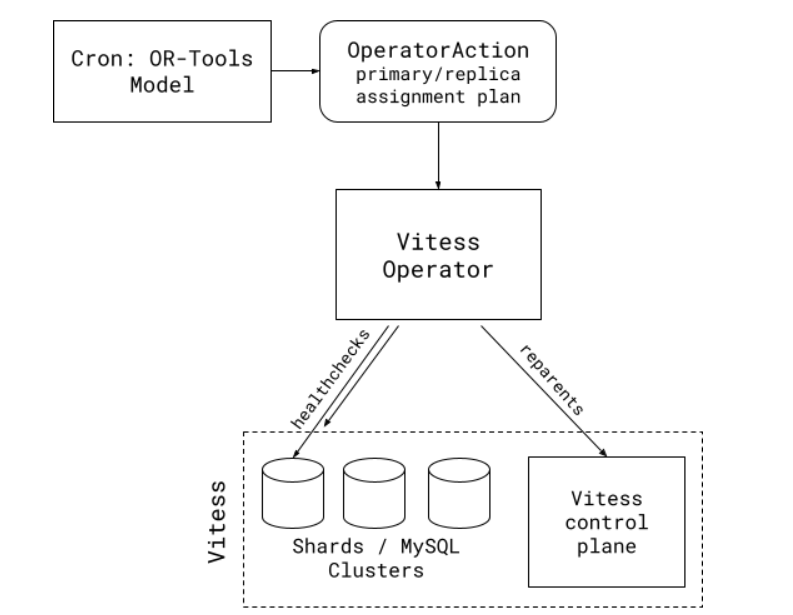
Figure 5: Vitess Balancer. Comprises a model to create plans for primary/replica assignment and an operator to execute plans.
With our model built and operator extended to execute plans, our Vitess Balancer was complete. We could now put it into practice to balance our primary/replica assignments.
Results: Near-Perfect Balance
So how did we do? It turned out that our Vitess Balancer works even better than expected, often achieving perfect balance across availability zones and greatly decreasing imbalance within Kubernetes nodes.
For instance, in one recent scenario, a particular datacenter had some Kubernetes nodes with 15 primaries running on them, and one availability zone had 7x more primaries than another (!). When the Balancer next ran, it achieved perfect balance across availability zones, and brought the max primaries-per-node down to 5. That’s a 3x reduction in primaries that can fail at once.
(How did those availability zones get so skewed? Throughout the process, we learned that, for reasons we haven’t fully explored, our rolling restart automation consistently introduces skew by depleting one availability zone over the others. The node/zone skew we were worried about was not just theoretical or left up to chance, but actually magnified by our own automation!)
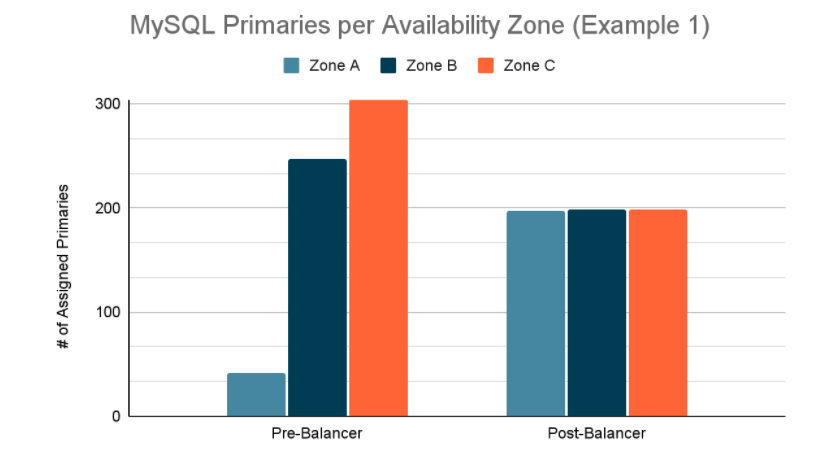 Figure 6: MySQL primaries assigned per availability zone, before and after the Balancer executed its reparenting plan. This scenario is one of the most dramatic differences we’ve seen the Balancer make, achieving perfect balance through 155 reparenting operations.
Figure 6: MySQL primaries assigned per availability zone, before and after the Balancer executed its reparenting plan. This scenario is one of the most dramatic differences we’ve seen the Balancer make, achieving perfect balance through 155 reparenting operations.
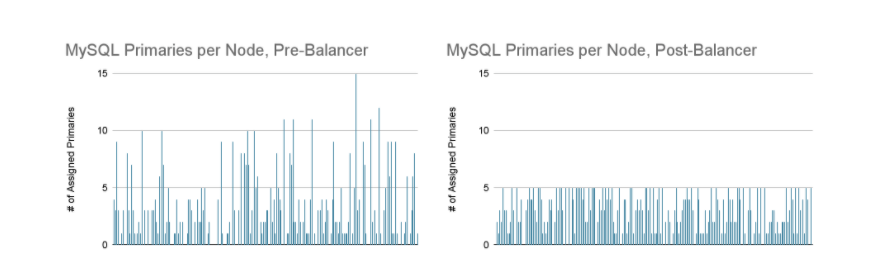
Figure 7: MySQL primaries assigned per node, before and after the Balancer executed its reparenting plan. These data are from the same scenario depicted in Figure 6.
More typically, we see the Balancer make minor adjustments throughout the day, improving our balance by a few primaries per availability zone, like this recent run that brought max-primaries-per-node from 5 down to 4, and reduced zone skew from 9 to 2:
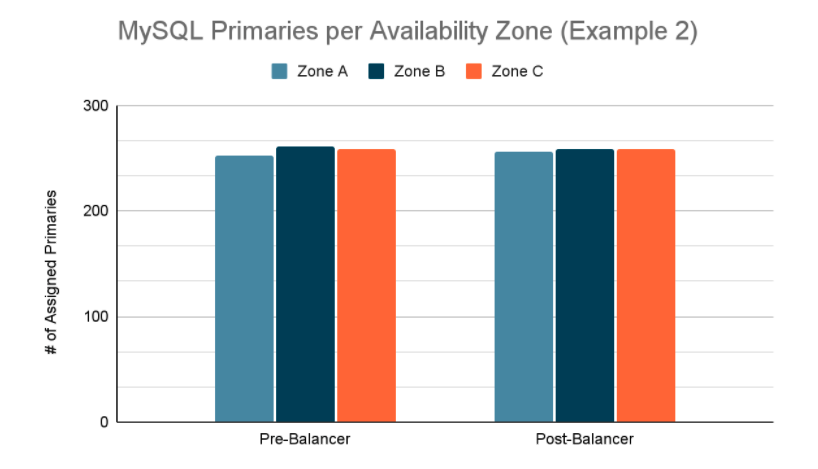
Figure 8: MySQL primaries assigned per availability zone, before and after Balancer executed reparenting plan. In this example, the Balancer executed 5 reparenting operations. This scenario is typical of the Balancer’s daily activities.
The Balancer typically achieves the best possible distribution of primaries across zones, and it has halved our worst-case primaries-per-node numbers from ~10 to ~5 in most datacenters. Now, when nodes do fail, the failure is more contained and therefore our automation and on-call engineers are able to more quickly restore all affected clusters.
One neat unanticipated use case we discovered is that we could leverage the Balancer to evacuate an availability zone, meaning that when one availability zone is having extended networking issues, we reparent all of our MySQL clusters out of that zone. Previously, the few times we’ve needed to do this, we did the operation by hand or with a quick script. But since we now had the Balancer, which could automatically generate primary/replica assignment plans and knew how to execute them, why not use it to do the reparenting instead?
We updated the Balancer to block primary assignments to problematic availability zones when computing a plan, such that when the Balancer generates and executes its plan it effectively reparents all primaries away from the problematic zone(s). Once the issue in the availability zone is resolved, we reinclude the zone in the computation and the Balancer starts redistributing primaries back into the zone on its next run. This use of the Balancer resulted in a much faster, more reliable, and better-balanced strategy than our prior manual efforts.
That concludes our work and findings on the Vitess Balancer so far - hope you enjoyed the ride! We found the constraint solver OR-Tools to be quite an accessible tool that allowed us to tackle a problem that would have been otherwise tricky to solve. The Balancer has been humming along improving our primary/replica assignments for about 18 months now. It’s been a reliable piece of our SQL infrastructure, requiring almost no maintenance since the first month it was deployed, yet quietly helping out and lowering the chance of high-severity failures in the background.
Want to work on a team that's just as invested in how you work as what you're working on? Check out our open positions and apply.