Improving Reliability: Building a Vitess Balancer to Minimize MySQL Downtime
After noting how a single hardware failure could domino into high-severity database outages, HubSpot engineers used constraint solving to build a ...
Written by Olga Shestopalova, Data Infra Engineer @ HubSpot.
HubSpot runs over a thousand MySQL clusters in each environment, and we were faced with the daunting task of upgrading all of these in a safe, automated manner. We jumped 9 major versions of Vitess, the clustering software we use for MySQL, along the way developing reusable testing tooling and automation to make all future upgrades significantly easier. This time around our upgrade journey took a year, but our estimate for the next upgrade is only a quarter, given all that we have learned and developed. Read on to learn more about our recent upgrade.
_________________
Vitess is the clustering software we use for MySQL. It was originally in use at YouTube and several of the engineers worked to open-source it under their own company called PlanetScale. HubSpot was an early adopter of Vitess in 2017 because it helped solve three growth problems for us: (1) clean API for administration of the servers, (2) fine grained and automatic failovers, and (3) sharding. It has worked really well for us, especially around scaling databases, automated recovery, and automation around database actions as a whole. It has let us step away from the dev-ops role we used to be in, and focus on higher-level and higher-impact tooling and automation, leveraging the Vitess server administration API. One example of what we did with this non-dev-ops time was the development of VTickets.
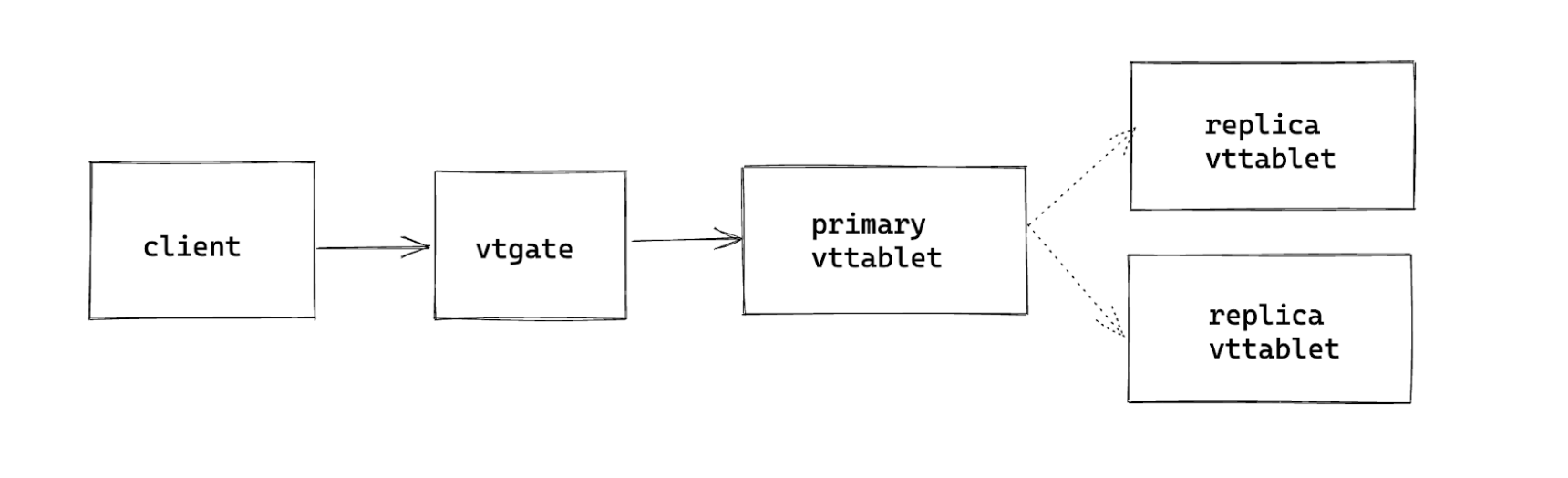
Vitess has two additional concepts not present in MySQL: vttablets and vtgates. Vttablets can be considered a direct mapping to MySQL servers, and vtgates are a proxy layer that sits between the client and the vttablet and directs traffic to the correct place (crucial for sharded databases). We run our cluster setup with one primary and two replicas, using regular MySQL replication.
We started off on Vitess 5, which was released in March 2020 (2.5 years old at the start of our upgrade process). How did we fall so far behind? After we adopted Vitess, we spent over 2 years migrating everyone over to Vitess. Meanwhile PlanetScale released 3 new versions. After we migrated every database over, we learned a lot about how we wanted it to change; we built new APIs into it, fixed some authentication bugs and made it stable. Meanwhile PlanetScale released 3 new versions. We went multi-datacenter and introduced VTickets (cross-datacenter auto-incrementing id generation). Meanwhile PlanetScale released 3 new versions. You get the picture.
The target version of Vitess was 14, and by the time we were done, PlanetScale was on the cusp of releasing Vitess 17. We could have upgraded version by version, but given we have over 1,000 clusters in each environment and we want to upgrade safely, it would have taken us about a quarter per upgrade. It would take us over 2 years to get from version 5 to 14 if all we did was upgrade, and then we’d be over 2 years behind, again.
So instead, we decided to do just one upgrade and jump from version 5 to 14. Our requirements were that this needs to have zero downtime and needs to be easily reverted in case of emergency. As such, we put in a lot of effort before we even begin to upgrade to instill confidence and develop the automation and tooling to allow us a hands-off, granular rollout.
Here’s the overview of what we wanted to accomplish:
The very first step of porting over our custom patches (changes we made to the codebase outside of the normal Vitess release) took much longer than we anticipated; the codebase between Vitess 5 and 14 had changed greatly, and we had more patches than we thought. It became our post-upgrade goal to upstream as many of our patches as possible to decrease this patching time in the future. A big reason we had fallen behind on upstreaming was due to the fact that we were so far behind in versions.
A big requirement of ours was that this upgrade be gradual, and we be able to roll back at any point, so we needed backwards compatibility between the versions. We had done preliminary research before embarking on this project and knew which parts were not backwards compatible, and therefore needed changes before we could continue. The majority of this was various renamings of RPC calls, which we forward-ported to our old version. We kept as many changes as possible confined to the old version, so we would have the fewest possible new patches in the new version. We then made follow-up issues to drop those patches in the new version once the upgrade was complete.
We then have our preliminary testing steps: ensuring that the new version works for our setup and our automation. In our case, this required some changes on the infrastructure side (again, mostly from renaming or restructuring of returned values), though thankfully not too many.
Then we pointed product team unit tests to Vitess 14. For HubSpot, this is over 900 repositories’ worth of MySQL unit tests, so it caught a large percentage of all issues we saw during this entire upgrade. For MySQL unit tests with Vitess, we use a tool called vtcombo, which combines the vtgate and vttablet behavior into one binary to simulate actually running against a Vitess cluster. We did this with existing automated background job tooling that ran the new Vitess 14 code against all repositories with MySQL unit tests and informed us of the results, and we ensured that we had resolved all errors before actually merging in the change so as to not disrupt product team development.
Once we had built confidence that everything worked with the new version, it was time to actually start the upgrade.
The simplest way to accomplish this would be to treat it like a regular code change, deploy out the changes, rolling restarting all vttablets and vtgates. Regular code changes go through canary deploys, which add safety, but not enough for this massive change. The problem here is that you’re deploying it out to everyone, so if one cluster has an issue, you have to stop, and roll it back for everyone. What’s more, vtgates are shared among all clients, so once the deploy reaches those, all clients will see the change. This makes for quite a large blast radius if something goes wrong.
Ideally, we would want to be able to control the vtgate version and vttablet version for each cluster individually.
The way we accomplish this is by essentially copying everything over into a new Vitess installation, complete with all vtgates and vttablets. Vitess calls this complete package a “cell”. We have our existing cell, running Vitess 5 code, and this new cell, running Vitess 14 code. If this pattern is beginning to sound familiar, it’s because we are following the blue green deployment pattern.
Our copies of vttablets still communicate with one another via MySQL replication, and there is still just one primary for each cluster, but many replicas. We control which copy of the vttablet is the one visible to clients by electing one to be the cluster primary. Cross-cell replica reads are not supported in our setup, which makes all replicas of the cell opposite the primary’s essentially invisible to the client.
We control which vtgates clients communicate with by implementing per-cluster DNS records, which, for each cluster, will direct the client to communicate with a specific vtgate in the desired cell. This is a live value; clients will check if the DNS record was updated every minute, so we can change it seamlessly behind the scenes without any need to restart a service to pick up the change.
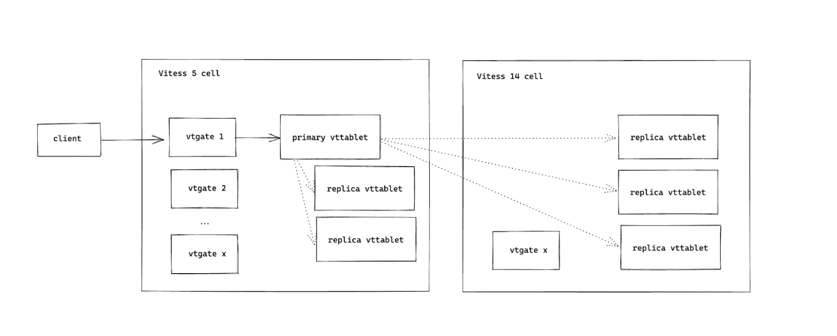
Something incredibly useful comes out of this “shadow replica” design - we have Vitess 5 and 14 vttablets running side by side, and we can replay read traffic against the Vitess 14 replicas and compare results. Therefore, if there are any changes that make some queries error out or return different results or are noticeably worse in performance, we will catch that before it affects any customers. This adds to our vision of building the most confidence before any changes can be seen by teams.
We tested for discrepancies in row count, time of execution, errors, and presence of syntax errors. All but syntax errors would have some amount of leeway to account for timing differences and transient blips, but any amount of syntax errors needed to be flagged, as these were always an issue that needed to be addressed.
The way we did this was by having one special vtgate, the logging vtgate, which would log all SELECT queries and their results/timings to disk, which would get rotated and shipped off to s3, and then a worker would read these and replay them against the upgraded replica for the given cluster, and compare the returned results. Our goal was to have the same timing for the queries as they had arrived in, so if there was a burst in queries, we would replay it as a burst as well, to get similar performance. To accomplish this, we had a delay of 1 minute between when the actual query was executed and when we would schedule the replay of that query, to accommodate for lag in shipping to s3/reading from s3, but then all queries would get scheduled to be executed at the same cadence they had originally been executed in.
One drawback to this method was that clusters with query patterns that would write a row, read that row, and then immediately delete that row in quick sequence would give us false negative results. This was because the “shadow replica” would replicate the write and delete almost exactly at the same time they happened, so the read that happened in the middle that waited an extra minute would return no rows. We worked around this by adding an extra step whenever we found a row count discrepancy, we would retest by sending the query back to the downgraded replica, and if the row count discrepancy was still there, then it was legitimate.
This method proved to be excellent at finding syntax errors in queries not covered by unit tests, and in a way that did not affect any customer traffic. The only thing this missed was performance regressions around certain delete patterns, since we only replayed SELECTs. In future versions, we plan to also query replay INSERT/UPDATE/DELETEs, though this design would have to be reworked to accommodate that.
Once a cluster passes query replay, we proceed to upgrading its vttablets.
In the beginning state, clients use:
Our next step is to maintain Vitess 5 vtgates but start using Vitess 14 vttablets. We don’t want to do both switches at once because if something breaks, it will be harder to debug where exactly the problem was.
To point client traffic to a Vitess 14 vttablet, we make the primary vttablet a vttablet that is running Vitess 14 code. Vitess calls this a reparent, which is the same as a MySQL-level primary/replica swap. This action is a very regular action built into Vitess itself and is meant to be entirely invisible to clients, with zero downtime.
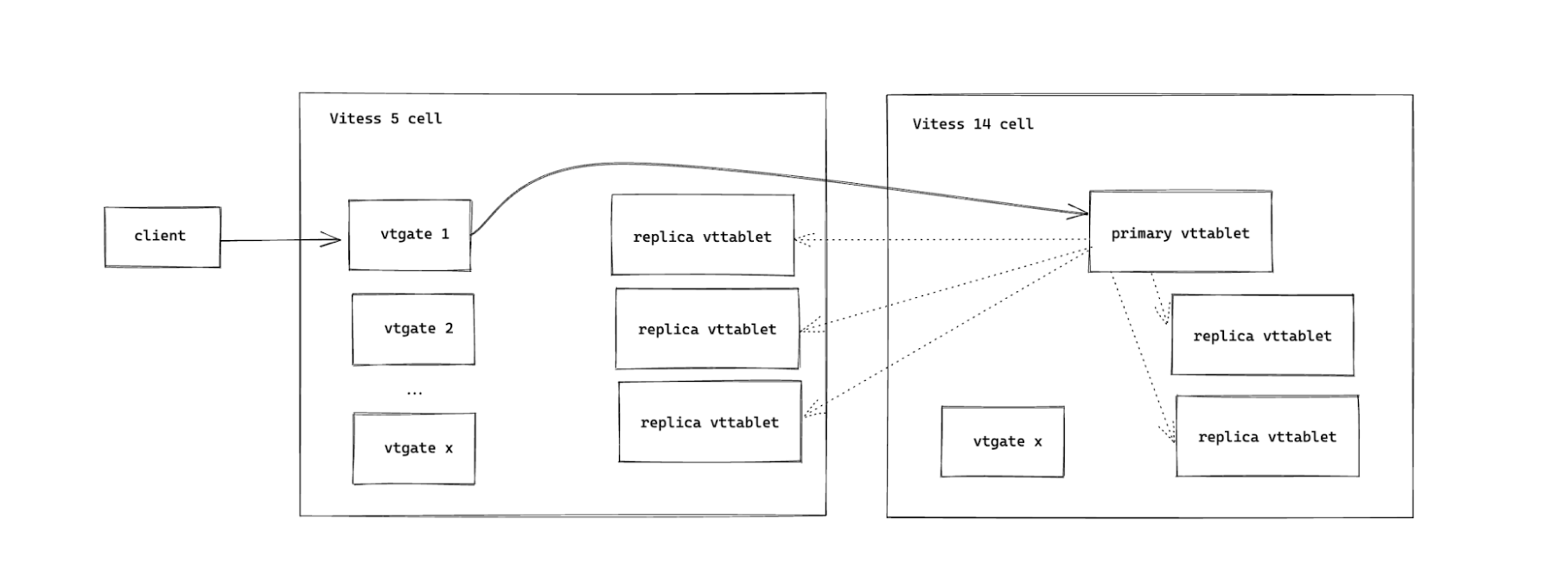
If we encounter an issue, the rollback here is simple, reparent back to make the primary vttablet a V5 vttablet.
The next step is to upgrade the vtgate that is used for a particular cluster. We have a DNS record per cluster that will tell it what vtgate address to use. Once we change this DNS record for the cluster, only clients connecting to that cluster will be using the upgraded vtgate; no other clients are affected.
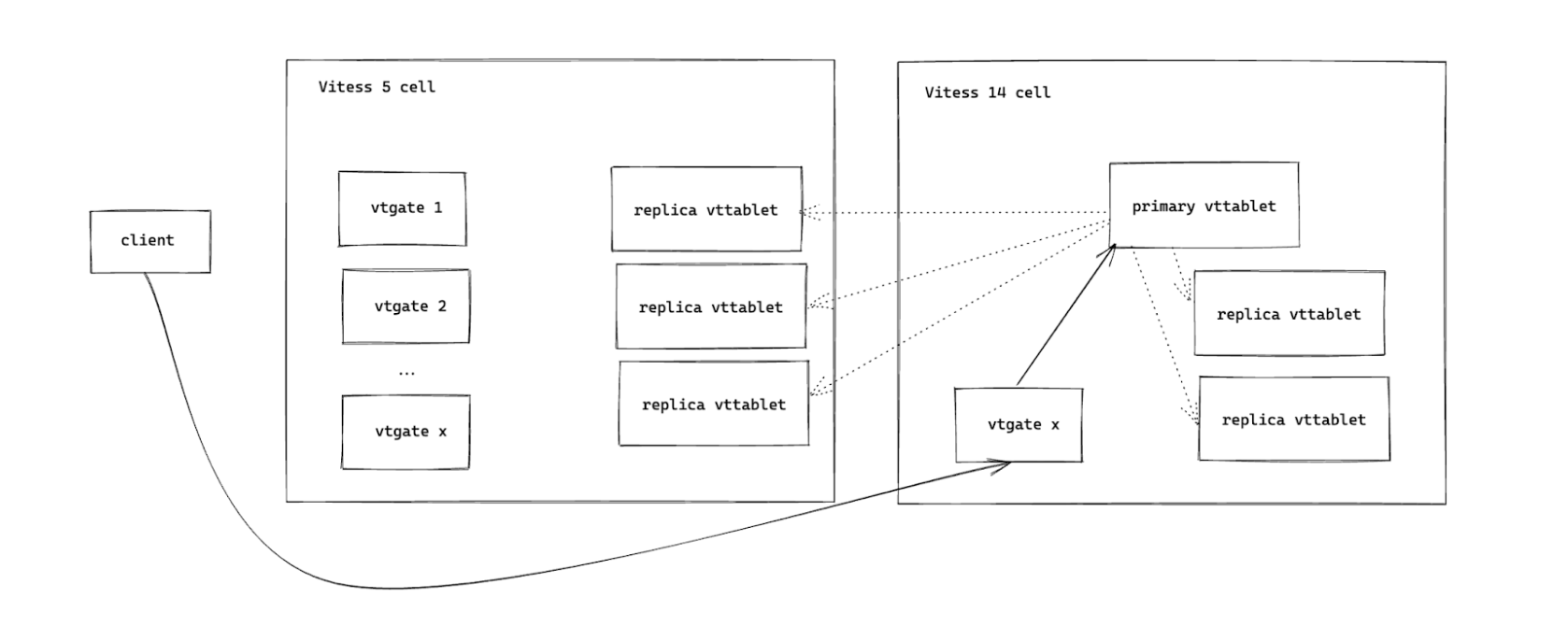 To rollback, we switch the DNS record back. As of our testing, this can take up to 2 minutes to be reflected in clients.
To rollback, we switch the DNS record back. As of our testing, this can take up to 2 minutes to be reflected in clients.
At the end of this step, the cluster is now fully upgraded, using both Vitess 14 vtgates and Vitess 14 vttablets. And the best part is, it’s entirely independent of the status of other clusters.
We had previously mentioned that a requirement of this upgrade was that it was automated and hands-off. This is crucial because we have over 1,000 clusters in each environment, so manual steps are slow and error-prone, and will only get worse as we grow. As such, we took the time to write a fully automated upgrade solution to handle this.
The automation consists of two parts: one part is the governing cronjob we call the Upgrade Launcher, and the other is a worker that executes Upgrade Actions that runs in every environment, called the Supervisor.
The Upgrade Launcher runs once a day at the start of the workday, and finds which clusters need to be progressed to which stages of the upgrade (creation of the cluster in the new cell, enabling of query replay, upgrading of vttablet if query replay has succeeded, upgrading of vtgate, teardown of the cluster in the old cell). It limits the number in each phase to a configurable number (we started with 10, and slowly progressed to 50). It then submits Upgrade Actions to the Supervisors in each environment, who actually carry out the tasks.
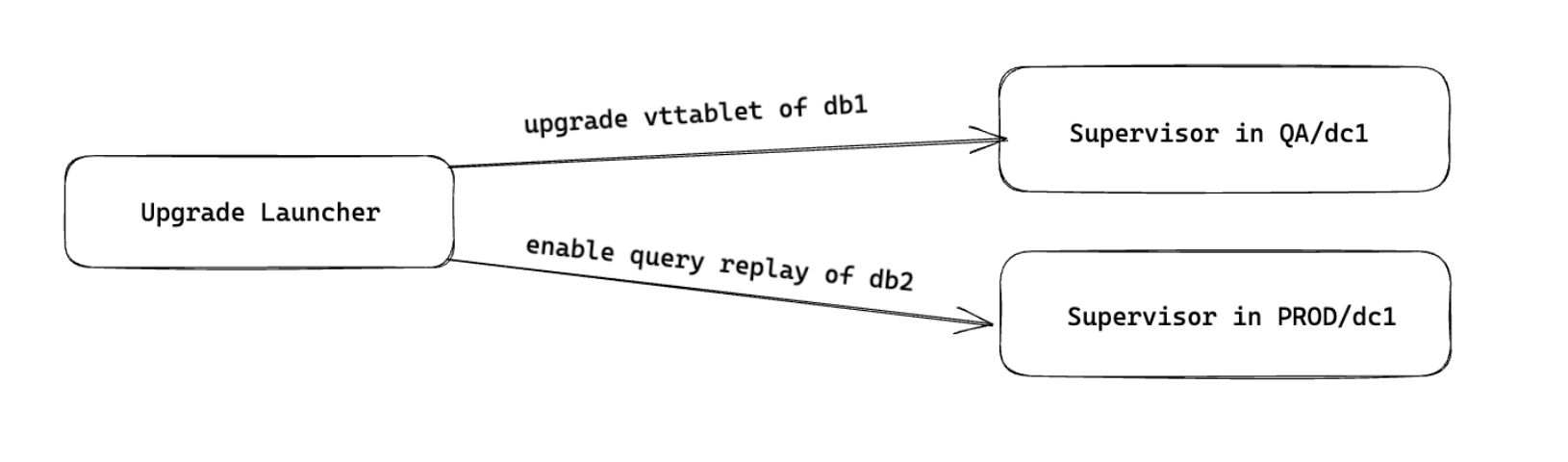
We had set up certain rules that the Upgrade Launcher follows, such as time between QA and PROD environment upgrades, and time between each of the steps (eg. run query replay for 2 days before upgrading the vttablet). The Supervisors would each inform us of the steps they took by reporting to Slack, and we set up a dashboard to monitor which cluster was in which stage of the upgrade in which environment. This allowed us to have full visibility into the process while having to take no manual steps for this to continue.
The only manual steps we had to take were investigative steps if a cluster did not pass query replay, or if a problem was detected by our alerting or by a product team reporting it that was right after an upgrade.
It took us a year to roll out this upgrade, from the patching and building tooling phase all the way through completion of rollout to production environments. The actual rollout took only 4 of those months, and we anticipate the next upgrade taking approximately a quarter - and most of this time being hands-off time, both due to the automation we have built up to support it, and to the fact that we will no longer be egregiously behind on Vitess versions and as such have an easier time in the patching and testing phase.
Naturally, there were a few bumps along the way. One such bump was a change in behavior of a DELETE - previous Vitess versions had rewritten inefficient DELETE queries to be a SELECT to find primary keys, and then a DELETE by those primary keys. Later versions of Vitess did no such thing, leading to a performance degradation in these kinds of queries. We did not catch this until we upgraded clusters with this query pattern, as our query replay was limited to SELECTs. We worked with teams to optimize their DELETE queries on their end to resolve this.
Another surprise was a client-level change. The Java client for Vitess is located in the same repository as the server code, but in our setup, we had two separate forks- one with the client patches and one with the server patches. As the Java client had not seen any changes over the many years, we assumed it was ok to leave as is and not fast-forward that fork. However, one thing we missed was a field addition to an error protobuf, and this manifested itself in a very unusual way, with a situation that should have resulted in an error, not resulting in an error due to this missing field. This led to some confusing behavior that was difficult to debug. After the upgrade was completed, we merged the code paths of our client and server code, which both upgraded the client and ensured we would not make this mistake in the future.
We also discovered some transactional queries we had that were poorly designed and broke under Vitess 14. Some of our queries were streaming queries that were inside of a transaction. Conceptually this doesn’t work because streaming queries have their own connections that ignore the transaction logic. In Vitess 5 this partially worked. The queries would complete (however the streaming parts of the transaction would take place outside of the transaction). In Vitess 14, streaming queries inside of a transaction were actually unable to complete and caused the transaction to freeze and time out. Rather than patching Vitess 14 to allow the flawed queries to execute, we removed the streaming queries so that all queries inside of a transaction would actually stay within the transaction.
We are aiming to stay upgraded within a year of the latest Vitess release, as it will take us approximately a quarter to upgrade, and we now have all the automation and tooling to help us jump several versions quickly and safely. We are taking several steps to make our upgrade process even smoother.
One such step is to upstream as many of our patches as possible. This is beneficial to us and to the Vitess community, as we have implemented certain improvements and enhancements that we would like to share with others.
Another step would be to ensure the mistakes we made in the last upgrade don’t happen again. We’ve upgraded our client and merged the code paths with our server code to guarantee that they do not diverge. We are also planning on improving our query replay to include writes as well as reads, so as to catch any issues such as the DELETE query regression in testing and not by the time it hits customers.
This is a very exciting time for us, as we have invested a lot of time and effort into this tooling, reaped the benefits of a very successful upgrade, and now have a path forward to even better, faster, safer upgrades.
Are you an engineer who's interested in solving hard problems like these? Check out our careers page for your next opportunity! And to learn more about our culture, follow us on Instagram @HubSpotLife.