Our Journey to Multi-Region: Supporting Cross-Region Kafka Messaging
This is the last installment of a five-part series about HubSpot’s year-long project to rework our platform for multi-region support. Check out the ...
In this post, we will explore HubSpot's strategy for handling MySQL auto-increment ids. This is the third installment of a five-part series about HubSpot’s year-long project to rework our platform for multi-region support. Check out the introduction to the series here.
HubSpot has a large MySQL footprint based on Vitess, a database clustering system originally developed at YouTube. We have nearly 5,000 tables, spread across over 800+ separate MySQL databases (called keyspaces in Vitess terminology). Of these, 75% have at least one table that employs an auto-increment primary key.
As part of our "pod" architecture approach to multi-region, each Hublet runs an independent copy of our MySQL infrastructure. This is great because it creates strong isolation between Hublets and allows for horizontal scaling, but it creates a challenge when it comes to auto-increment ids. The issue is that the MySQL servers in each Hublet don't communicate or know about each other, and by default, they also maintain totally separate auto-increment sequences. As a result, we can end up with duplicate ids across Hublets. For example, the Files table in na1 and eu1 could both store a File with id=123.
But why is this a problem? Each Hublet is isolated, so who cares if they both have a File with id=123? The first issue is that we inherently expect some ids to be globally unique. For example, HubSpot customer ids are generated via auto-increment, and we don't want to have multiple customers with the same id. We have some internal business systems that run in a centralized fashion (rather than running independently in each Hublet), such as our billing system. These systems would get very confused if there were two HubSpot customers with the same id. Also, we know that someday we want to allow customers to migrate between Hublets. For example, an EU company might have started out in our US data center, but now wants to migrate to our EU data center. We expect that this migration process will copy data directly from na1 to eu1. If we have duplicate ids in any of our databases, then we'll run into unique key violations when we attempt this migration.
At this point, it was really tempting to say that auto-increment and Hublets just don't play well together, and devise some sort of UUID replacement. However, we talked about the value of detangling in the previous post. We didn't want the EU data center launch to be blocked on migrating thousands of tables, owned by hundreds of different engineering teams, off of auto-increment. We had to find a way to make a globally unique auto-increment system, while still meeting the performance and reliability goals of the overall Hublets project.
Enter VTickets: this is an extension to Vitess that we built which provides unique id generation across our multiple datacenters.
To restate the problem we’re solving, we need a system external to MySQL that provides auto-incrementing ids unique across datacenters with the following constraints:
A simple design we briefly considered but ultimately did not fit our constraints was to use the Sequences feature built into Vitess. Sequences is backed by a single, unsharded database in one datacenter and can grant unique ids across datacenters. However, it would require every insert in the EU to make a call to the US to get an id, which is not acceptable from a latency or reliability perspective. Additionally, each Hublet runs an entirely separate Vitess topology, which precludes the use of Sequences.
The Basics
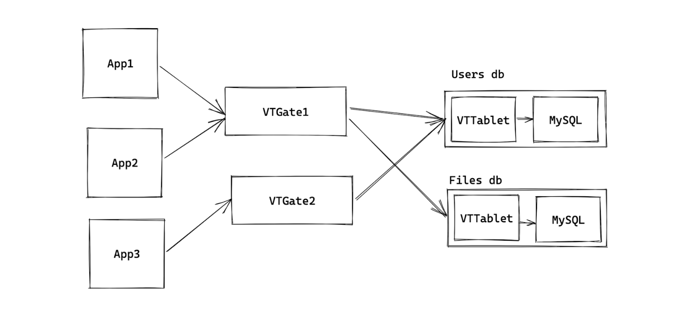
We use Vitess to manage our MySQL databases, which adds two things to our setup: the VTGate, which is a proxy that sits between all clients and all databases, and the VTTablet, which is essentially a sidecar to each MySQL process. When a client issues a query, it first passes through the VTGate, which redirects it to the appropriate database, where it enters the VTTablet sidecar process and then MySQL, returning back through VTTablet and VTGate and to the client. VTGates are shared among all clients and databases, but there is exactly one VTTablet for each database instance.
The VTGate has the capacity to rewrite queries to be suitable for a sharded database. One of these rewrites is to supply auto-incrementing ids from an external source for sharded databases. For example, if there are two shards of the Users database, each shard being its own MySQL instance, the two shards need an external source to provide them with auto-incrementing ids or there is no guarantee of uniqueness. This external id system doesn’t function across datacenters, but it does provide us with an easy entrypoint to patch in our VTickets system.
In each VTGate as an insert comes in, if the configuration of the database indicates that it has an auto-incrementing field that requires VTickets (this configuration is called a VSchema), we modify the insert statement to add a special annotation to the field to indicate it needs a VTicket.
The VTTablet sidecar can also modify the query as it comes in, and in our system, we have it take notice of any VTicket annotations, and replace them with a generated id. That way, by the time the query reaches MySQL, it already has an auto-incremented id in place and MySQL does not need to generate anything on its own.
 Keeping Track of Ids
Keeping Track of Ids
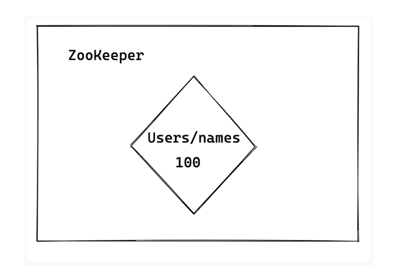
We use ZooKeeper to keep track of the highest ids that have been issued for each database and table. For the sake of our example, let’s say we have the Users database with the names table, and the highest id issued so far is 100. This would translate to ZooKeeper storing this high watermark of 100 for Users/names.
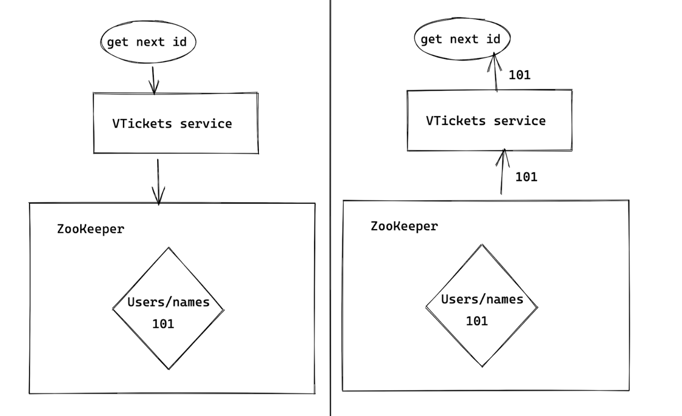
 We then have a service on top of this that grants requests for more ids by incrementing the highest id stored in ZooKeeper, returning the ids that can be used by the database for that particular table. To continue our example, once the Users database/names table needed more ids, the high watermark in ZooKeeper would increase to, say, 101, as that id of 101 is granted to be used for an insert going into Users/names.
We then have a service on top of this that grants requests for more ids by incrementing the highest id stored in ZooKeeper, returning the ids that can be used by the database for that particular table. To continue our example, once the Users database/names table needed more ids, the high watermark in ZooKeeper would increase to, say, 101, as that id of 101 is granted to be used for an insert going into Users/names.
First Steps
The simplest design would be to have each database primary (our setup includes one primary and two replicas) ask the VTicket service for a new id each time an insert came through that required one. For example, if we were to insert into the EU Users database, names table, the primary would ask for another id, which would be 101. If the NA Users database/names table received an insert, it would get the next available id, which would be 102.
End to end, this would look like the client making an insert query, which passes through a VTGate and gets a special annotation, then the VTTablet would make an api call to the VTickets service to replace that annotation, and finally MySQL would complete the insert with that id already generated.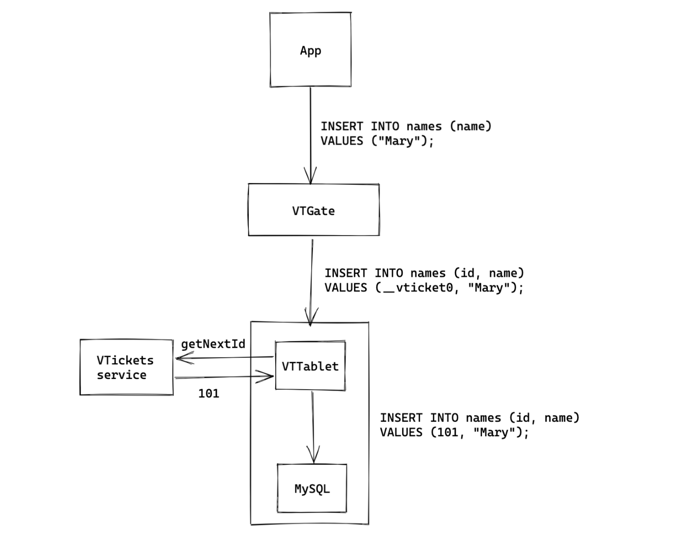 This is a good starting point as it preserves monotonicity, but this is not ideal for several reasons. It introduces a single point of failure, and would also be terrible for insert latency, as it would require a service call each time an insert came through. If the service were to become slow or go down, all inserts would fail or become slow, which is unacceptable.
This is a good starting point as it preserves monotonicity, but this is not ideal for several reasons. It introduces a single point of failure, and would also be terrible for insert latency, as it would require a service call each time an insert came through. If the service were to become slow or go down, all inserts would fail or become slow, which is unacceptable.
Two Layers of Services
Building on that idea, however, we introduce the notion of a datacenter-level VTickets service and global VTickets service. We have exactly one global VTickets service, which is backed by ZooKeeper as described above. We then have a datacenter-level VTickets service in each datacenter. This datacenter-level VTickets service is essentially a cache to avoid requesting ids from the global service each time. Both global and datacenter-level VTickets services are backed by ZooKeeper.
In this improved design, the global VTickets service grants batches of ids to the datacenter-level VTickets services for each database and table. Then, each database primary requests batches of ids for each of its tables from the datacenter-level service. Therefore, the global service can be down for some amount of time without causing a HubSpot-wide outage, as each datacenter-level service is independent of each other.
Back to our example, suppose our batch sizes were 100: the EU Users database/names table would request more ids from the EU datacenter-level VTickets service. This would either have a cache or request more from the global service, storing that it has ids [101-201). The datacenter-level service would then return back id 101 to the database. The NA equivalent would request a batch from the NA datacenter-level VTickets service, which would either have a cache or request more from the global service, storing that it has ids [201, 301). The datacenter-level service would then return back id 201 to the database.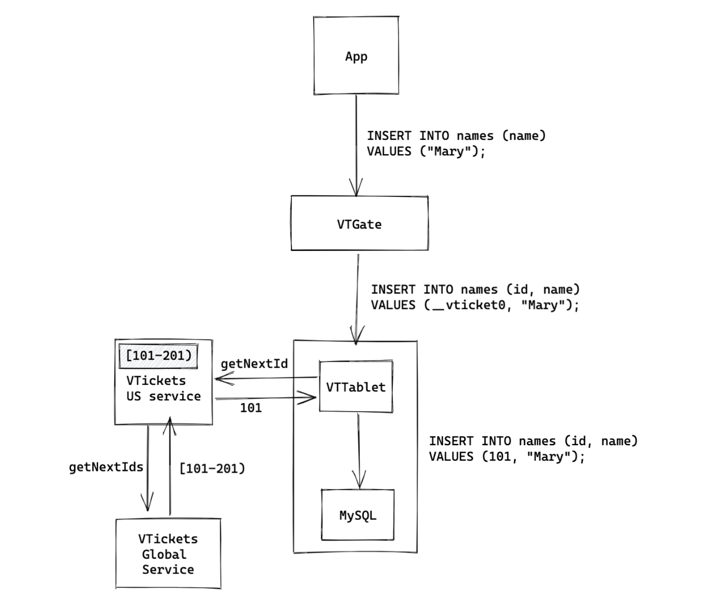
This helps with reliability, however, this doesn’t resolve the matter of insert latency, or how to withstand a datacenter-level VTicket service outage.
Caching
To remediate that, we introduce caching at the database primary level. Instead of requesting an id on every insert, the primary asynchronously requests batches of ids for each of its tables from the datacenter-level VTicket service. It stores these, using them up as inserts come through. This allows us to both withstand a datacenter VTicket service outage and removes the need for an insert to wait on a service call, improving insert latency.
For example, when an insert comes in for our Users database, names table, the database primary first checks its cache for any available ids. Only if the cache is empty does it fall back to making a request to the datacenter-level VTickets service. Which in turn also has a cache, falling back to the global VTicket service.
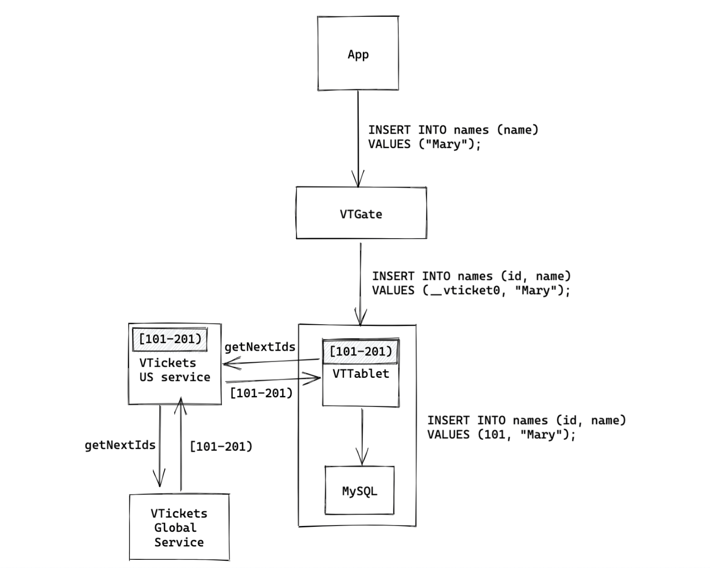
Our goal is to never have the primary ask the datacenter-level service for more ids while blocking an insert, and likewise, never have the datacenter-level service ask the global service for more ids while blocking a request. Therefore, our cache refills happen asynchronously as the system notices the cache getting too low. This asynchronous refill happens at both the database primary level as well as the datacenter-level VTicket service level.
With these improvements, we now have a cross-datacenter MySQL auto-increment replacement that does not increase insert latency and can withstand outages of its dependencies.
Cache Sizing
When deploying this new system, our biggest challenge was correctly sizing the database primary cache. This cache represented how many ids were stored in memory on the database primary for each table. Note that we support a variety of insert rates and patterns, including abrupt spikes, representing high customer activity.
If the cache is sized too small, then it is possible for inserts to use up all the available ids too quickly, and have to wait for a service call to get more ids from the datacenter-level VTickets service. This would impair insert latency, and reduce our ability to withstand a datacenter-level outage.
However, database primaries are frequently swapped/restarted during our regular development cycle or during failovers, a result of which is that this in-memory cache would be lost. Therefore, the larger the cache, the more ids we potentially lose, and it’s possible that we burn through the id space too quickly.
The cache needs to be sized correctly: large enough to be able to withstand spikes in insert rate without waiting for a service call for more ids, but not so large that we needlessly lose large swaths of ids during regular primary swap operations.
Initial Approach
At HubSpot, we have a notion of performance classes for our databases, based on the resources they require. For example, databases that only need several CPUs and some memory are categorized as “small,” databases that require more resources are “medium,” and so on with “large.”
Our initial idea was to size the cache according to these performance classes. The heuristic was that databases that needed more resources were likely also performing more inserts than their smaller counterparts.
When we deployed this change, it performed poorly for several reasons. The heuristic turned out to not be true for all databases; there were many “small” databases that handled a very large amount of inserts, and conversely, “large” databases that had virtually no inserts. Moreover, we assessed the performance class of the database, and sized the cache for all tables on the database identically, which didn’t account for differences in insert rates between the tables themselves.
QPS-based Sizing
Our next approach was to base the size of each table’s cache based on the insert query per second (QPS) rate it saw. This decouples the tables from each other, and uses a heuristic that is exactly tied to the rate at which ids are requested. The formula is as follows: for each table, we track insert QPS over the past 15 minutes, and use an exponentially weighted average to estimate how many ids we should asynchronously request to sustain our QPS with some breathing room. This also dynamically adjusts the threshold at which we refill our cache.
For example, a table that has been inserting at 10 QPS and then suddenly spikes to 100 QPS would quickly see an increase in the number of ids requested per service call as well as an increase in the frequency of which the calls to get ids are made, to sustain the spike without running out. Conversely, once the spike falls back down to 10 QPS, we would see fewer calls with smaller batch sizes requested each time. The exponentially weighted average allows us to take fast action based on the current situation (weighted more than the past), without overreacting by considering what we had seen in the past (weighted less, but still present).
When we deployed this system out, we saw the batch sizes requested adjusting to bursts of traffic, and no inserts waiting on a service call. Some of our highest insert QPS databases have a sustained cache size of 6 million, and we can see instances of a database with one table requesting several million ids in one go, and another table fluctuating from 200 to 5k, so we hone in on the right number for reliability and performance without burning excess ids.
To summarize, we size the cache of ids in the database primary’s memory that is proportional to how many the table has needed in the recent past, using the past insert rate to predict future insert rate.
Reliability vs Id Space Consumption
Sizing the in-memory cache based on QPS also makes it easy to quantify how VTickets affects the rate of id consumption. For example, let's say we have on average 15 minutes of ids in memory on the primary, and we do one primary swap a day. This means we can withstand a 15-minute outage of the datacenter-level VTicket service and also that on the primary swap, we’re burning 15 minutes worth of ids. With one primary swap a day, that means we lose 15 minutes out of the 1440 minutes in a day, which is 1.04%, meaning that with this level of reliability, we burn through ids 1.04% faster.
To get a bit more aggressive, say we perform a primary swap twice a day and want to have on average 30 minutes of ids in memory. This means we would be losing 60 minutes of ids per day out of the 1440 minutes in a day, which comes out to burning through ids 4.16% faster, and being able to withstand a 30 minute outage (which is quite a long time for a service to be down).
On the other hand, if we assume we perform a primary swap once every two days, and we still want to maintain the 15 minutes of ids in memory, that means we would be losing 15 minutes of ids out of the 2880 minutes in two days, which comes out to burning ids 0.52% faster than normal.
Results
To zoom out, the VTickets system was built to be a cross-datacenter replacement for MySQL auto-increment that has fault-tolerance built into it by having both global and datacenter-level services, and adaptive caching at every level.
We have had VTickets running on our 800+ production databases successfully for over a year now, supporting databases that run tens of thousands of inserts per second. This opened the door to our cross-datacenter journey, all the while maintaining performance and increasing reliability as we isolate our datacenter-level failures from each other.
Stay tuned for our next post in the series explaining the systems we use for keeping global MySql data in sync.
Other multi-region blog posts:
These are the types of challenges we solve for on a daily basis at HubSpot. If projects like this sound exciting to you, we’re hiring! Check out our open positions and apply.