Our Journey to Multi-Region: VTickets, Hublet-Compatible MySQL Auto-Increment
In this post, we will explore HubSpot's strategy for handling MySQL auto-increment ids. This is the third installment of a five-part series about ...
This is the last installment of a five-part series about HubSpot’s year-long project to rework our platform for multi-region support. Check out the introduction to the series here.
Communicating via Kafka is a core part of many systems at HubSpot. As of July 2022, we have roughly 4,000 Kafka topics spread across 80 clusters. As we started to think about multi-region support for Kafka, the plan was relatively straight-forward. We create a copy of each Kafka cluster in each Hublet, and we create a copy of each Kafka topic in each Hublet. So there is a contact-updates topic in na1, and there is an equivalent contact-updates topic in eu1. When applications produce to Kafka, they automatically produce to the cluster in the current Hublet. And when applications consume from Kafka, they automatically consume from the cluster in the current Hublet. With this setup, interacting with Kafka works automatically in each Hublet without changing any application code. And data and data processing is automatically isolated between Hublets. This is great for performance, reliability, and data localization. However, there are a handful of use-cases where this isn't the behavior we want.
The way this relates to Kafka is that our billing system publishes Kafka messages about billing events, and application code relies on consuming these messages. But since our billing system only runs in na1, an application in eu1 won't be able to see any of the Kafka messages it produces. Similarly, if an application in eu1 produces a Kafka message that our billing system needs to consume, it won't work because our billing Kafka consumers only see messages in na1.
We evaluated existing tools designed for inter-cluster data flows like Kafka’s MirrorMaker or Confluent Replicator and decided that, given the low number of use cases and their relatively low data volume, it wasn’t worth introducing new dependencies to our infrastructure. Instead, we decided to build our own simple aggregation system for this use-case. We already had well-supported building blocks for each part of the design, we just needed to add a little bit of glue to wire things up.
The way we handle this is by creating a special "aggregated" topic, in this case trial-events-aggregated. This topic only exists in na1, and will contain the union of all the trial-events messages from all Hublets. Our billing system can then consume from trial-events-aggregated and see all messages globally, which is exactly what we want.
But how does data get into the trial-events-aggregated topic? The way this works is that when you opt a Kafka topic into the aggregation system, we launch a special Kafka consumer in each Hublet. So in this case, there is a special aggregation consumer running in each Hublet that is consuming the trial-events topic. This consumer takes each batch of messages and makes an API call to the Kafka aggregation API, which only runs in na1. This Kafka aggregation API is configured to accept cross-Hublet API calls (which are disabled by default). The Kafka aggregation API then takes the batch of messages and produces it to the trial-events-aggregated topic.
Here's a diagram with the whole data flow: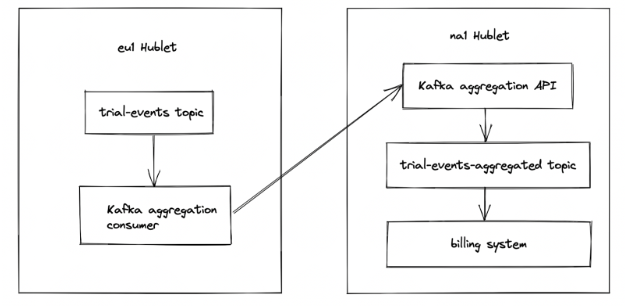
Theoretically we could remove the Kafka aggregation API and have the aggregation consumer produce directly to the aggregated topic in na1. However, our guardrails make this difficult, because of how the network and credentials are locked down between Hublets. Because of this, making an API call is generally the recommended way for systems to communicate across Hublets.
Note that in the diagram there is only one cross-Hublet call, and it happens in our Kafka aggregation consumer. This consumer isn't latency sensitive and it can easily retry failed requests indefinitely (thanks to the way Kafka consumers keep track of their offsets). Additionally, messages get produced to the aggregated topic in the same order as the original topic. So our Kafka aggregation system attempts to preserve message order, in case it's important.
Here's a diagram with the whole data flow:
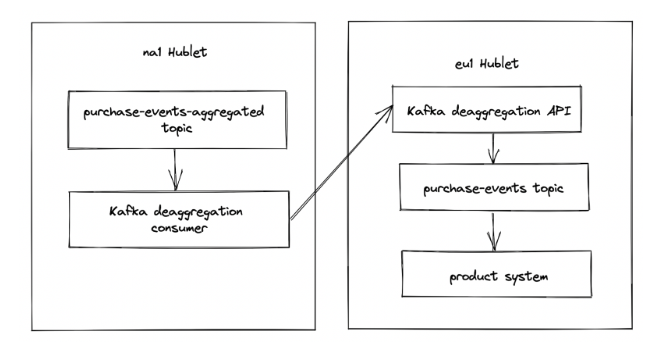
Similar to before, there is only one cross-Hublet call, and it happens in our Kafka deaggregation consumer. We run a separate instance of this consumer for each Hublet, that way if one Hublet is having issues, the consumers for the other Hublets can continue making progress.
Closing Thoughts
This system allows data to be transferred between Hublets, and therefore must be used judiciously. Enabling Kafka aggregation or deaggregation is a non-trivial process that requires approval from the team that owns the Kafka topic, the Hublets team, and the Kafka team. As part of this we review the system design and try to find alternatives, and we also review the Kafka message schema to ensure that there is no PII or other customer data involved.
We have been running Kafka aggregation and deaggregation in production for more than a year now, and it has worked very smoothly. Currently, the aggregation consumer and deaggregation consumer both use the high-level consumer API, and each topic consumer runs in a separate process. This is great for isolation, but it's relatively resource inefficient. In the future, we may switch to the low-level consumer API and run all of the consumers in a single process. This design would add complexity, but it would utilize the underlying hardware much better.
This concludes our multi-region blog series. Thanks for following along, and stay tuned for more content in the future.
Other multi-region blog posts:
Check out the previous blogs in our series to understand our process and lessons learned. And read up on other interesting projects and challenges we've work on over on our product blog.