Single-node hotspotting is a common source of reliability problems for systems that use distributed databases. At HubSpot, we recently introduced client-side request deduplication in order to prevent hotspotting in HBase.
Background
Up until a few years ago, whenever a backend engineering team at HubSpot needed to store new kinds of data for a new application, they would typically spin up their own MySQL or HBase table for that data. This approach worked well initially, but over time, different backend engineering teams would repeatedly implement the same features on top of these databases. When all you're starting with is raw MySQL or HBase, extra engineering effort is required to implement features like making the data searchable via Elasticsearch, making the data available in HubSpot's reporting tools, allowing users to import new data, and integrating the data with HubSpot's automation and workflows.
To prevent engineering teams from reinventing the wheel, these features and many more were all wrapped up into a system we internally refer to as the HubSpot Framework. Now, instead of provisioning their own databases to power their applications, HubSpot engineering teams often use HubSpot Framework APIs to manage their data. The HubSpot Framework effectively acts as a replacement for using a raw database, giving engineering teams a toolbox of powerful features to build applications.
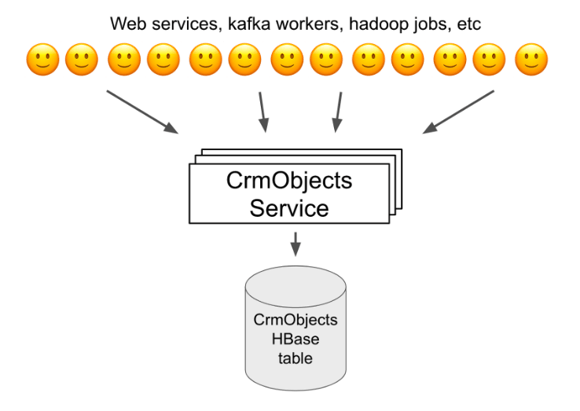
Under the hood, most of the data in the HubSpot Framework is stored in HBase. One of the key primitives in the HubSpot Framework is CrmObjects. For those familiar with the HubSpot product, things like contacts, deals, and custom objects are all examples of CrmObjects. These days, a wide variety of data powering the HubSpot product is internally represented as CrmObjects.
One consequence of this architecture where many teams are storing their data as CrmObjects is that different types of data owned and accessed by many different teams are all stored inside of a single table in a single HBase cluster. Hundreds of web services, background workers, and cron jobs owned by dozens of different engineering teams read and write CrmObjects data hundreds of thousands of times per second. As we will see, this architecture introduces new challenges in maintaining a reliable system.
HBase Hotspotting
CrmObjects are stored in HBase, a horizontally scalable, distributed database used at HubSpot for storing big data. For a given HBase table, data is split up among multiple servers that HBase calls RegionServers. Each row in the table is managed by exactly one RegionServer.
Each object is represented as a single row in the CrmObjects HBase table, meaning all of the data for a given object lives on exactly one RegionServer. Internally, HBase ensures that data for a given table is evenly distributed across all RegionServers in the cluster. This means that each RegionServer handles roughly the same number of CrmObjects. As the total number of CrmObjects increases, and as the rate of reads and writes to the database increases, we can add more RegionServers to handle the extra scale. So expanding on the above diagram, the CrmObjects backend actually looks more like this:
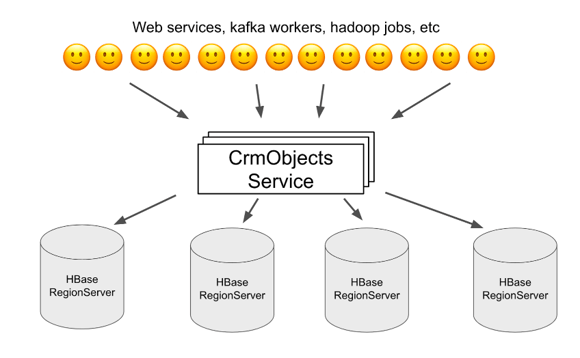
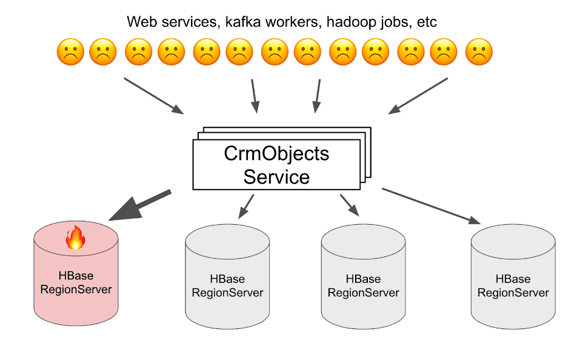
Horizontal scaling of HBase works great if the traffic we're sending to the database is uniformly distributed across all RegionServers. However, we often run into pathological cases where a single client repeatedly reads the same CrmObject as many as 10,000 times per second. Because all of those reads need to be sent to the same HBase RegionServer, that RegionServer can quickly become overloaded and experience degraded performance. We call this scenario hotspotting. Even though it's typically only a single upstream caller causing the hotspotting, all upstream callers experience degraded reliability and performance when a RegionServer is hot, so it's important that we prevent this from happening.
Non-ideal solutions
When this problem is described, the first solution that comes to many engineers' minds is to introduce caching, that way we don't need a database read for every single request to the CrmObjects service. This would prevent hotspotting, but unfortunately it's not a viable solution because CrmObjects guarantees that it never serves stale data. Databases often call this a "strong consistency" guarantee. HBase provides strong consistency, and by extension, CrmObjects always has as well. This guarantee is heavily relied on by many clients of CrmObjects, so caching and then potentially serving stale data is not an option for us.
Another option might be to just rate limit callers and prevent them from sending a high rate of read requests for a single object. Again, this would prevent hotspotting, but it causes degraded performance for the caller being rate limited, and depending on what caller is being rate limited, this can result in a bad experience for HubSpot users.
Request deduplication
The solution we landed on was deduplicating requests to HBase inside of the CrmObjects service. If CrmObjects receives a bunch of simultaneous, identical requests for the same object, instead of sending one HBase request per CrmObjects request, we can just send a single request to HBase for that object!
To see how this works, let's first look at a normal request to the CrmObjects service. The CrmObjects service gets a request to read an object, it immediately fetches that data from HBase, and then it returns that data to the caller.
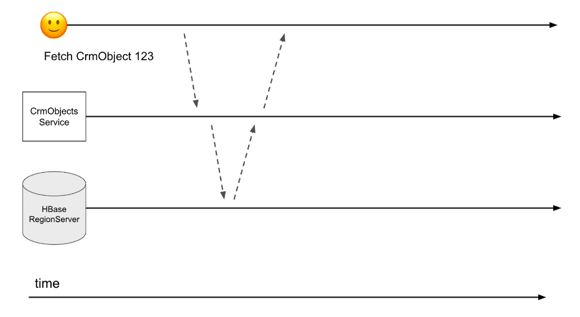
However, now when the CrmObjects service receives a request for a hot, frequently accessed object, instead of immediately fetching that object from HBase, we'll wait for up to 100ms to see if any more incoming requests will also request that same object. At the end of the 100ms window, the CrmObjects service will send a single request to HBase for that hot, frequently accessed object, and it uses the single HBase result to respond to all the clients who asked for the hot object in that 100ms window.
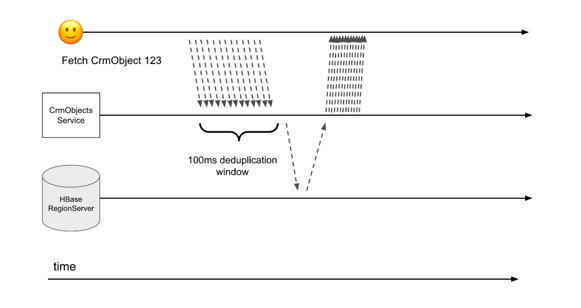
Request deduplication prevents hotspotting, and unlike caching, it does not sacrifice strong consistency.
Why 100ms? you might wonder. This duration is somewhat arbitrary, but the idea is that the longer this window is, the longer that requests sent at the beginning of the deduplication window will have to wait for a response. However, if the window is too short, our deduplication will be ineffective, and we again become susceptible to RegionServer hotspotting. 100ms was a good middle ground to account for these two concerns. Keep in mind though that this tradeoff of latency vs. deduplication effectiveness only applies to the small minority of requests that are asking for hot objects. The vast majority of requests to CrmObjects are handled by immediately fetching data from HBase with no delay.
Problem: High instance count
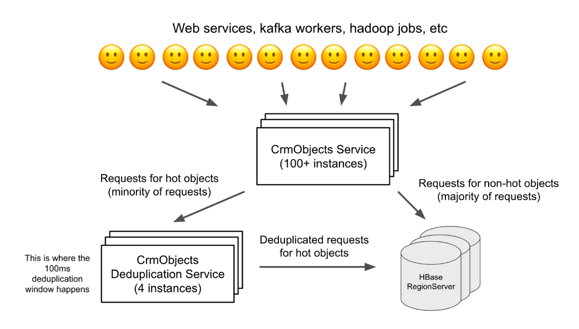
With a 100ms deduplication window, a given instance of the CrmObjects service can send at most 10 requests per second to HBase for a given object, and an HBase RegionServer can handle that rate of requests easily. However, because of how heavily the CrmObjects APIs are used across HubSpot, we need to run this service with over 100 total instances.
With request deduplication, even if each instance of this service is sending only 10 requests per second for a given object, across all instances, we can still end up sending over 1000 requests per second to the RegionServer hosting that object. For large objects, that rate of requests is enough to cause RegionServer hotspotting.
Could we solve this problem by routing all requests for a given object to just a single instance of the CrmObjects service? Unfortunately, there are problems with that approach:
- We’d potentially start hotspotting individual instances of the CrmObjects service.
- Single requests to CrmObjects can ask for multiple objects at a time. For requests that want multiple objects, it is unclear which instance we would route them to.
- Even if it was a viable approach, application-specific load balancing rules are very uncommon at HubSpot. We want to conform to HubSpot standards.
The solution here was to have the CrmObjects service proxy all requests for hot objects through a separate web service that runs with only 4 instances, and now that separate web service is the one that does request deduplication. Because there’s only 4 instances of that separate web service, overall, we will send at most 40 requests per second to HBase for a given hot object (4 instances * 10 requests/second/instance). HBase RegionServers can handle that load comfortably. Most requests to CrmObjects are for non-hotspotted objects, so the main CrmObjects service with 100+ instances still handles those directly. Only the small minority of requests for objects that have been identified as hot are proxied through the request deduplication service.
Results
Before implementing HBase request deduplication in CrmObjects, we’d frequently encounter periods of degraded performance due to hotspotting. Every couple months or so, the hotspotting would be severe enough to meaningfully impact our users’ experience, and an engineer would have to reach out to the team causing the hotspotting to have them reduce their rate of requests.
Below are some metrics collected during a load test of request deduplication. For this load test, we repeatedly read a single object 10,000 times per second. The top chart shows the rate of requests from the load test into CrmObjects.
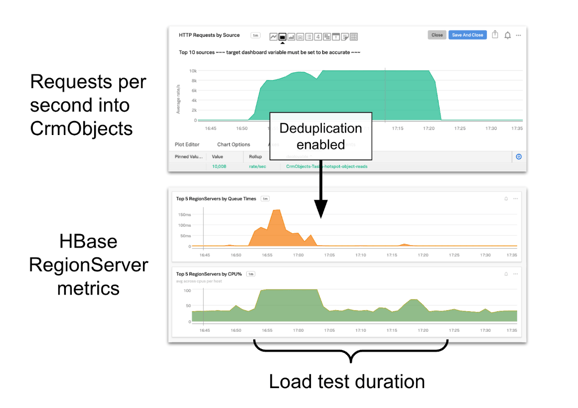
The bottom two charts show queue times and CPU usage on the RegionServer hosting the hot object. At the beginning of the load test, request deduplication is disabled, and the RegionServer experiences degraded performance. Halfway through the load test, request deduplication is enabled, and the RegionServer becomes completely healthy. This is because the rate of requests from CrmObjects to that RegionServer drops dramatically.
Since enabling CrmObjects request deduplication in January of 2022, we haven’t seen any HBase hotspotting in this system. All of the applications that are built on top of the HubSpot Framework benefit from this improvement, and the end result is a more consistent, reliable experience for HubSpot’s users. This is just one example of how we build infrastructure at HubSpot: solve for scale and reliability at lower layers of the stack so that engineering teams higher in the stack can focus on delivering products and features to customers.
Want to work on a team that's just as invested in how you work as what you're working on? Check out our open positions and apply.