Tuning G1GC For Your HBase Cluster
HBase is the big data store of choice for engineering at HubSpot. It’s a complicated data store with a multitude of levers and knobs that can be ...
Serving over 2.5 PB of low latency traffic per day, HubSpot’s Data Infrastructure team has seen first hand how important locality can be for HBase performance. Read on to learn more about what locality is, why it matters, and how we’ve made maintaining locality a non-issue in our ever growing HBase clusters.
Some of HubSpot’s largest data sets are stored in HBase, an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable. We have almost 100 production HBase clusters, comprising over 7000 regionservers across two regions in AWS. These clusters are serving over 2.5 PB of low latency traffic per day and since each AWS region is made up of multiple datacenters, we’ve determined that locality is critical to keeping those latencies in line.
What is locality?
HBase data is stored in HDFS, which by default replicates your data 3 ways:
This is all well and good, but HBase data is also split into contiguous chunks called regions. Regions need to be able to quickly move from host to host in order to maintain availability when, for example, the hosting RegionServer crashes. To keep things fast, the underlying data blocks don’t move when a region moves. HBase can still happily serve data for the region by remotely fetching blocks from whichever of the 3 replicas hosts are still available.
In a highly optimized single datacenter, a remote host fetch may have minimal impact on latencies. In the cloud, those replica hosts may not be in the same building or even the same part of town as the requesting RegionServer. When running latency sensitive applications, this extra network hop can have a dramatic effect on end-user performance.
Locality is the measure of what percent of a RegionServer’s data is stored locally at a given time, and it’s a metric we monitor very closely at HubSpot. In addition to the network latency, HDFS also has a feature called “short circuit reads”. When data is local, short circuit reads allow the client (HBase) to read data files directly from disk rather than having to go through the colocated HDFS DataNode process at all. This further reduces latencies that may come from the TCP stack or DataNode process itself.
Over the years, we’ve periodically run performance tests to validate the effect of locality on latencies. Here are some results from our most recent test:
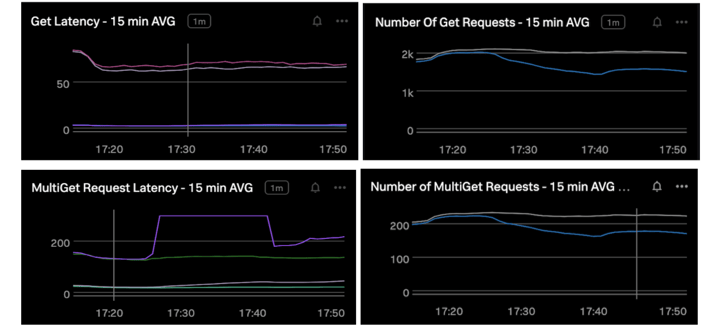
All four charts have the same time window. I disrupted locality on the treatment cluster at the start of this time window. As you can see, individual Get latencies (top left chart) were marginally affected, but throughput (top right) dropped significantly. MultiGets were significantly affected in latency (bottom left) and throughput (bottom right). We find that in general MultiGets are extra sensitive to latency regressions because they hit multiple RegionServers and are typically at least as slow as the slowest target.
Here’s one more example from a production incident we encountered a few months ago:
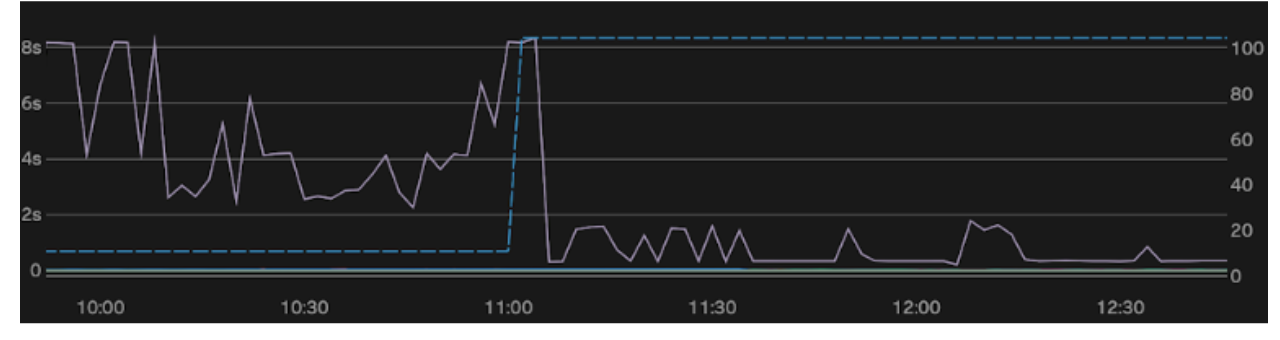
This cluster has a relatively small dataset, but was under heavy load. The left axis (light purple) is the 99th percentile latencies while the right axis (dotted blue) is locality. During the incident, locality was around 10% and latencies were between 2-8s. With the tooling we’ll be discussing in this post, we solved the issue around 11:00 – bringing locality to 100% in only a few minutes, which reduced latencies to under 1s.
Resolving locality issues
Locality can take a dip for a variety of reasons, all stemming from regions moving:
For us, all three of these reasons are relatively common. When locality dips, you have two options:
Data in HBase is initially written to memory. When the in-memory data reaches a certain threshold, it is flushed to disk resulting in immutable StoreFiles. Since StoreFiles are immutable, updates and deletes do not directly modify the data. Instead they are written to new StoreFiles, along with any other new data that has come in. Over time you build up many StoreFiles, and these updates must be reconciled with older data at read time. This just-in-time reconciliation slows down reads, so background maintenance tasks run to consolidate StoreFiles. These tasks are called compactions, and they’re broken down into two types: major and minor.
Minor compactions simply combine smaller, adjacent StoreFiles into bigger ones to reduce the need to seek between many files to find data. Major compactions rewrite all StoreFiles in a region, combining into a single StoreFile with all updates and deletes cleaned up.
Going back to the definition of locality, our goal is to ensure that the newly hosting server has a local replica for every block in the StoreFile. Through existing tooling, the only way to do that is to re-write the data, which goes through the block placement policy described above. To that end, major compactions make a lot of sense since they involve rewriting all data. Unfortunately they are also very costly:
That cost is baked into every major compaction regardless of our locality goals, and can affect long tail latencies itself. Typically you only want to run major compactions off-hours, to minimize the impact to end users. However, locality has the biggest impact during on-peak hours, so that means potentially hours of pain while you wait for off-hours compactions to begin.
In terms of locality, there’s another hidden cost — it’s very possible that only some of a region’s StoreFiles have bad locality. A major compaction compacts all StoreFiles, so if only 1GB of a 10GB region is non-local, that’s 9GB of wasted effort from a locality perspective.
Here’s a chart from one of our clusters where we were trying to heal locality through compactions:
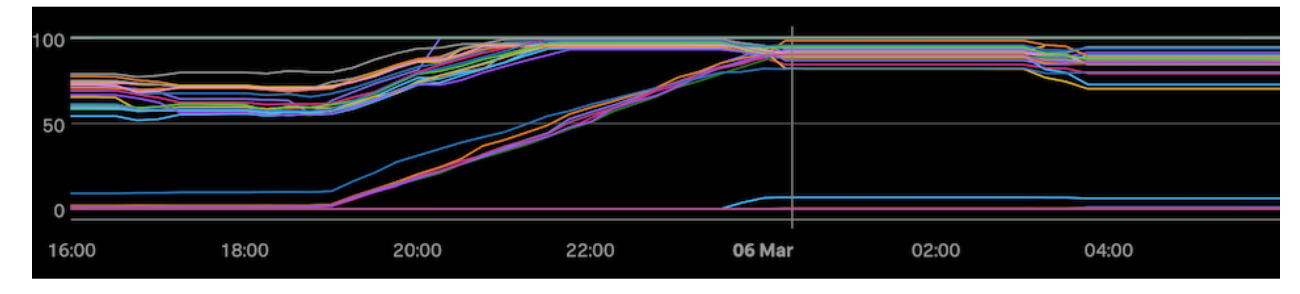
This chart shows a relatively large HBase cluster, with each line being the locality for an individual regionserver in the cluster. It took about 6 hours to slowly bring locality up to a peak of only around 85% before we ran out of time. A few hours later, an incident occurred which ruined some of the gains we made and we would not be able to run compactions again until the next night, based on the load patterns of the cluster.
Over the years, the above scenario has played out time and again. As we scaled, we were seeing more and more instances where compactions could not effectively heal locality fast enough for our SLOs. We needed a better way.
Cutting costs, and turning hours into minutes
I’ve been working with HBase on-and-off for many years, and this usage of compactions to solve locality has always frustrated me. I’ve long been aware of tools like the HDFS Balancer and Mover, which can do low level block moves. Having a similar tool, which uses low level block moves to heal locality, would be very appealing for a few reasons:
For this project, I wanted to see if we can build something similar for improving locality of low-latency applications.
Existing components
The first step I had to take in order to build our own block mover is to understand all of the various components that go into moving blocks, reading blocks, and calculating locality. This section is a bit of a deep dive, so if you just want to learn about our solution and the results feel free to skip ahead to the next section.
The Dispatcher
At the heart of the Balancer and Mover is the Dispatcher. Both tools pass PendingMove objects to the Dispatcher, which handles executing replaceBlock calls on remote DataNodes. The typical block size for an HBase cluster is 128mb, while regions are typically multiple GBs. So a single region might have anywhere from a dozen to a few hundred blocks, a single RegionServer might host anywhere from 50 to a few hundred regions, and a single cluster can have hundreds or thousands of RegionServers. The Dispatcher’s job is to execute many of these replaceBlock calls in parallel, keeping track of progress while the remote DataNodes do the work of copying data. This Dispatcher does not handle choosing which replicas to move, so I’d need to build a process to detect low locality regions and turn those into PendingMove objects.
Replacing a block
A remote DataNode receives the replaceBlock call from the Dispatcher, which includes a blockId, source, and target. Data is then streamed from the source to the target, through the proxy DataNode.
When the target DataNode finishes receiving the block, it notifies the NameNode via a RECEIVED_BLOCK status update. This status update includes a reference to which DataNode used to host the block. The NameNode updates its in-memory record of where blocks live, and flags the old DataNode as PendingDeletion. At this point, a call to fetch locations for a block will include both the new and old DataNode.
The next time the old DataNode reports in, the NameNode responds with “Thanks, now please delete this block.” When the DataNode finishes deleting the block, it again pings the NameNode with a DELETED_BLOCK status update. When the NameNode receives this update, the block is removed from its in-memory record. At this point a call to fetch block locations will only include the new DataNode.
Reading data with DFSInputStream
HBase creates a persistent DFSInputStream upon opening each StoreFile, which is used to serve all ReadType.PREAD reads from that file. It opens additional DFSInputStreams when STREAM reads come in, but PREAD are the most latency sensitive. When a DFSInputStream is opened, it fetches the current block locations for the first few blocks of a file. As data is read, these block locations are used to determine where to fetch block data from.
If the DFSInputStream attempts to serve data from a crashed DataNode, that DataNode is added to a deadNodes list and excluded from future requests for data. The DFSInputStream will then retry from one of the other block locations that are not in the deadNodes list. A similar process plays out if the DFSInputStream tries to fetch a block from a DataNode which no longer serves that block. In this case, a ReplicaNotFoundException is thrown and the DataNode is similarly added to the deadNodes list.
A single StoreFile could be anywhere from a few KB to a dozen or more GB. With a block size of 128mb, that means a single StoreFile could have hundreds of blocks. If a StoreFile has low locality (very few local replicas), those blocks will be scattered across the rest of the cluster. As DataNodes are added to the deadNodes list, it becomes increasingly likely that you’ll encounter a block for which all locations are in the deadNodes list. At this point, the DFSInputStream backs off (3s by default) and re-fetches all block locations from the NameNode.
Unless there is a more systemic problem at hand, all of this error handling will result in temporary increased latencies but no bubbled up exceptions to clients. Unfortunately, the latency hit can be noticeable (especially the 3s backoff) so there is room for improvement here.
Reporting on and making decisions based on locality
When a StoreFile opens on a RegionServer, the RegionServer calls the NameNode itself to get all block locations for that StoreFile. These locations are accumulated into an HDFSBlockDistribution object for each StoreFile. These objects are used to calculate a localityIndex, which is reported to clients via JMX, on the RegionServer web UI, and through the Admin interface. The RegionServer itself also uses the localityIndex for certain compaction-related decisions, and it reports the localityIndex of every region to the HMaster.
The HMaster is the HBase process which runs HBase’s own balancer. The balancer attempts to balance regions across the HBase cluster based on numerous cost functions: read requests, write requests, StoreFile count, StoreFile size, etc etc. One key metric it tries to balance is locality.
The balancer works by calculating a cluster cost, pretending to move a region to a random server, and re-calculating the cluster cost. If the cost decreases, accept the move. Otherwise try a different move. In order to balance by locality, you can’t simply use the reported localityIndex from RegionServers because you need to be able to calculate what the locality cost would be if a region moved to a different server. So the balancer also maintains its own cache of HDFSBlockDistribution objects.
The LocalityHealer
With an understanding of the existing components in hand, I started work on a new daemon we affectionately call the LocalityHealer. Digging deeper into the Mover tool, I came up with a design for how the daemon should work. The crux of the work here comes down to two pieces:
HBase makes available an Admin#getClusterMetrics() method which enables polling the state of the cluster. The returned value includes a bunch of data, one of which is RegionMetrics for every region in the cluster. This RegionMetrics includes a getDataLocality() method, which is what we want to monitor. So the first component of this daemon is a monitor thread which is continually polling for regions whose getDataLocality() is below our threshold.
Once we know which regions we need to heal, we have the complicated task of turning that into a PendingMove. A PendingMove takes a block, a source, and a target. What we have so far is a list of regions. Each region is made up of 1 or more column families, each with 1 or more StoreFiles. So the next step is to recursively search the region’s directory on HDFS for StoreFiles. For each StoreFile, we get the current block locations, choose one replica for each block as the source, and create a PendingMove for each block where the target is the currently hosting RegionServer. Our goal with choosing which source to move is to ensure we adhere to the BlockPlacementPolicy and minimize the amount of cross-rack network traffic.
Once we’ve handed off all of our generated PendingMoves to the Dispatcher, it’s just a matter of waiting for it to finish. When it’s finished, we wait another grace period for our locality monitor to notice the updated locality metrics and then repeat this whole process. This daemon continues this loop forever until it shuts down. If locality is at 100% (which it now often is), it sits idle until the monitor thread notices a dip.
Ensuring reads benefit from newly improved locality
So the daemon is running and ensuring that the DataNode on all RegionServers is hosting a block replica for all of the regions on that RegionServer. But the DFSInputStream only fetches block locations on initial open or in exceptional cases, while each StoreFile has a persistent DFSInputStream. In fact, if you’ve followed along you may be realizing that we might be seeing a fair amount of ReplicaNotFoundExceptions if blocks are moving around all the time. These actually cause pain and should ideally be avoided.
Ship it fast, with a v1
When I originally built this system back in March, I decided to use a callback function for refreshing reads in HBase. I was most familiar with HBase, and this was the path of least resistance. I pushed new RPC endpoints for both the HMaster and RegionServer to our internal fork. When the LocalityHealer finished healing all of the StoreFiles for a region, it called these new RPCs. The RegionServer RPC was particularly gnarly, with some complicated locking necessary. In the end what it did was re-open the StoreFiles, and then transparently close the old ones in the background. This re-opening process would create a new DFSInputStream with the correct block locations and update the reported locality values.
This has been deployed with great success ever since, but we are currently working on a major version upgrade and needed to make this work with the new version. This turned out to be even more complicated, so I decided to try to design a different approach for this part. The rest of this blog refers to the new v2 approach, which has been fully deployed since October.
Iterate and adapt
In investigating our major version upgrade I discovered that HDFS-15199 added a feature to the DFSInputStream to periodically refetch block locations while open. This seemed exactly what I wanted, but in reading the implementation I realized the re-fetch was built directly into the read path and occurred regardless of if it was needed. This seemed fine for that issue’s original goal of refreshing locations every few hours, but I need to refresh every few minutes at the most. In HDFS-16262, I took this idea and made it both asynchronous and conditional.
Now, DFSInputStreams will only refetch block locations if there are deadNodes or any non-local blocks. The refetching process happens outside of any locks, and the new locations are quickly swapped into place with the lock. This should have very minimal impact on reads, especially relative to existing locking semantics in the DFSInputStream. With the asynchronous approach, I feel comfortable running the refresh on a 30 second timer which allows us to quickly adapt as blocks move around.
Load testing
This new approach of asynchronously refreshing block locations means a bunch of DFSInputStreams all hitting the NameNode at various times. If locality is good, the number of requests should be zero or near-zero. In general when you’re running the LocalityHealer, you can expect your overall cluster locality to be above 98% pretty much all the time. So I was not concerned about this under normal circumstances. One thing I was concerned about is what it might look like if we had a total failure and locality went to near zero.
We prefer to split large clusters rather than let them get too big, so our largest cluster has about 350k StoreFiles. In a worst case scenario, all of those would be pinging the NameNode every 30 seconds. This means approximately 12000 req/s. My hunch was that this wouldn’t be a huge deal, since this data is entirely in-memory. We run our NameNodes with 8 CPUs and enough memory to cover the block capacity.
HDFS has a built in NNThroughputBenchmark which can simulate exactly the workload that I’d expect. I first ran this against a 4 CPU NameNode in our QA environment, using 500 threads and 500k files. This single load test instance was able to push 22k req/s, still leaving 30-40% idle CPU time on the NameNode. That’s more than double our worst case scenario, and was very promising.
I was curious what prod could do, so I ran it against an 8 CPU NameNode. It was easily able to push 24k req/s, but I noticed that the CPU was almost idle. I had reached the maximum throughput of the benchmark on the test host I was using. I started up another concurrent test against that same NameNode from another host, and saw the total throughput jump to over 40k req/s. I kept scaling out and eventually stopped at over 60k req/s. Even at that level, idle CPU was still over 30-45%. I feel confident that this load is no problem for our NameNodes.
Reducing pain
Early deployments of the locality healer did create a minor amount of pain when it was running. This all goes back to the ReplicaNotFoundExceptions I mentioned earlier, which sometimes result in costly backoffs. Back when I first worked on this, I submitted HDFS-16155 which added exponential backoff and allowed us to reduce that 3s down to 50ms. This went a long way in dealing with the pain, making it very manageable and worth the trade-off for long term improved locality.
As part of my investigation into HDFS-16262, I learned a lot more about how the invalidation process happens after a block is replaced. I briefly covered that in describing the components above, and it also gave me an idea for how I might eliminate this pain altogether. What if I could add a grace period around that “Please delete this block” message that the NameNode sends out? The result of that line of thought is HDFS-16261, wherein I implement exactly such a grace period.
With that feature in place, I configured a grace period of 1 minute on our clusters. This gives the 30 second refresh time in the DFSInputStream plenty of time to refresh block locations before blocks are removed from their old locations. This has eliminated ReplicaNotFoundExceptions, along with any associated retries or costly backoffs.
Reflecting updated locality in metrics and the balancer
The final piece of the puzzle here is updating that localityIndex metric I mentioned, and the balancer’s own cache. This part is covered by HBASE-26304.
For the Balancer I utilize the fact that RegionServers report their localityIndex to the HMaster every few seconds. That is used to build the ClusterMetrics object you query when calling getClusterMetrics, and it’s also injected into the balancer. The fix here was simple -- when injecting the new ClusterMetrics in, compare it to the existing. For any region whose reported localityIndex changes, that is a great sign that our HDFSBlockDistribution cache is out of date. Use that as a signal to refresh the cache.
Next up is ensuring that RegionServers are reporting the correct localityIndex in the first place. In this case I decided to derive the StoreFile’s HDFSBlockDistribution from the underlying persistent DFSInputStream that powers PREAD reads. The DFSInputStream exposes a getAllBlocks method, which we can easily convert into a HDFSBlockDistribution. Previously, the StoreFile’s block distribution was calculated on StoreFile open and never changed. Now that we derive from the underlying DFSInputStream, that value automatically changes over time as the DFSInputStream itself responds to block moves (as covered above).
Results
Case Study: Managing locality across 7000 servers
I’ll start off by letting the data speak for itself. We started rolling out the LocalityHealer to some of our more problematic clusters in mid-march, and finished rolling out to all clusters in early May.
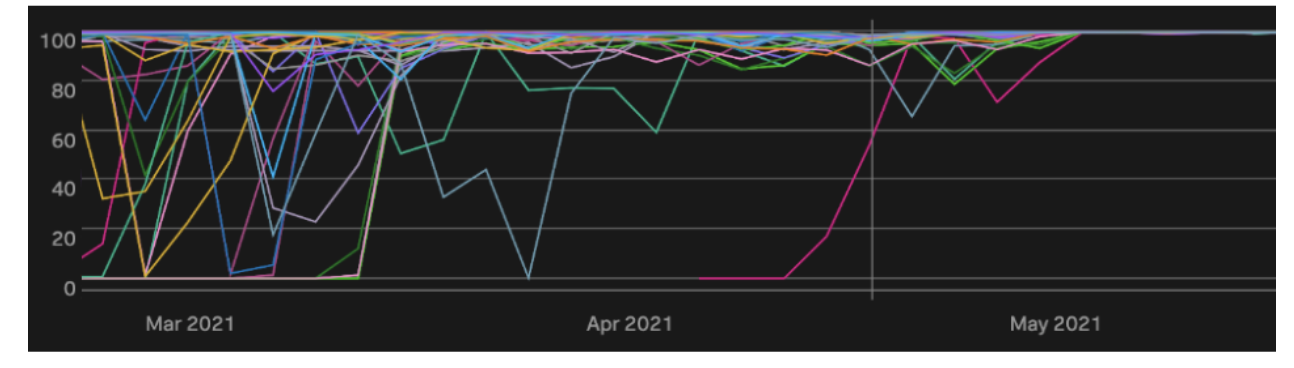
This chart shows the 25th Percentile locality values for all of our production clusters from from March 1, 2021 to June 1, 2021. Prior to March we see many dips down to less than 90%, with some clusters continually going down to almost 0%. As we started to roll out the LocalityHealer, those dips became less frequent and less severe. They were entirely eliminated once the LocalityHealer was fully rolled out.
We like to keep locality above 90%, but notice real problems start to arise when it goes below 80%. Another way to look at the issue is with the count of RegionServers whose locality dips below 80% in an interval.
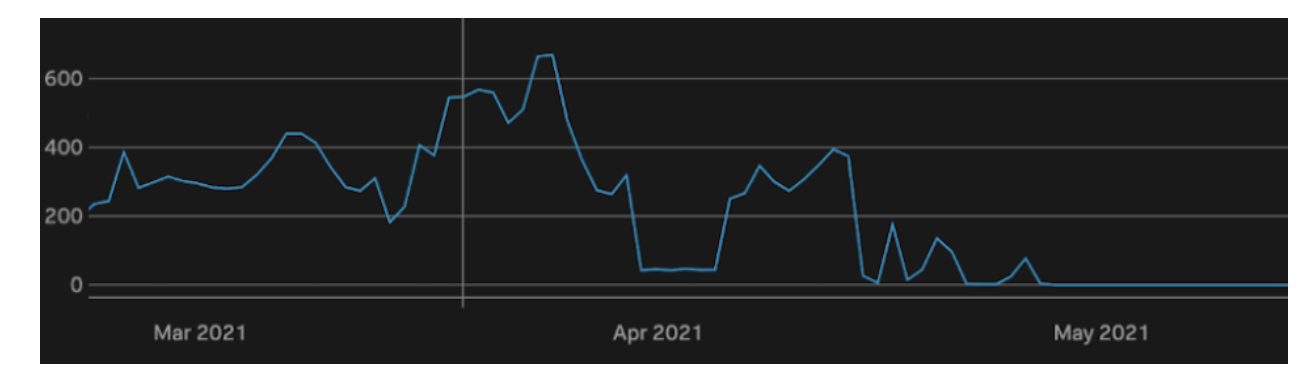
This chart shows the same time period as above, and you can see we used to have hundreds of servers below 80% locality at any given moment. Starting in early May that value is consistently 0, and remains to this day.
The best thing about these charts is it’s all automatic. We unfortunately don’t have metrics for alert volume due to locality, but anyone on the HBase team could tell you that they used to get paged pretty much daily for locality on one cluster or another. This was always an annoying alert to get, because the only thing you can do is kick off major compactions which take hours to finish. Over time we made our locality alerts less sensitive to avoid burnout, but this had a negative impact on cluster stability.
With the LocalityHealer, we never think about locality anymore. We can make our alerts very sensitive, but they never go off. Locality is always near 100%, and we can focus on other operational concerns or value work.
Case Study: Quickly resolving timeouts due to bad locality
Here’s one more example on a particular cluster which only hosts about 15TB. You can see near the start of the timeline, the brown line is a new server which launched with 0 locality. It took compactions about 7 hours to get up to about 75% locality, before running out of time. Later that night, more servers were added but it was too late to start compactions on them (due to other tasks like backups which run in the very early morning).

As we reached peak traffic the next day, the HBase team was paged by a product team who were experiencing timeouts that were resulting in 500’s for customers. At this point, the HBase team had two options:
They chose the latter, which brought the entire cluster’s locality to 100% in 3 minutes. Zooming in, you can see the impact below.
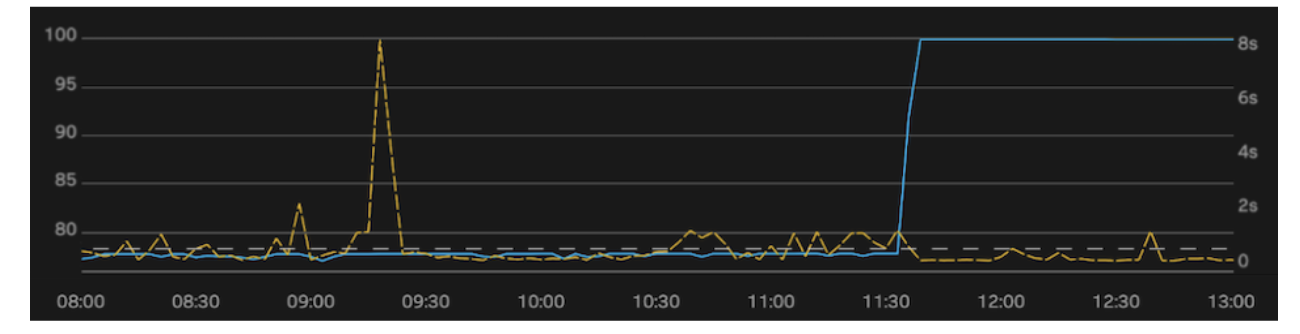
In this case I’ve summarized the first chart by plotting a single mean locality (left axis, blue line). I’ve overlaid the 99th percentile latencies for the cluster (right axis, yellow line). Throughout the morning we were seeing a growing number of timeouts (500ms, denoted by grey dotted line). We knew this would become critical as we reached peak traffic, so the LocalityHealer was run at 11:30. The jump of locality to 100% resulted in an immediate reduction in latency volatility and timeouts.
Conclusion
The LocalityHealer has changed the game at HubSpot when it comes to managing a key performance indicator across a rapidly growing fleet. We’re currently working on contributing this work to the open source community, under the umbrella issue HBASE-26250. If you’re interested, please feel free to watch or comment on that issue.
This is the sort of work that our Data Infrastructure team tackles on a daily basis. If projects like this sound exciting to you, we’re hiring! Check out our open positions and apply.