Using HBase Quotas to Share Resources at Scale
Written by Ray Mattingly, Engineering Lead, HBase @ HubSpot
Written by Ray Mattingly, Technical Lead @ HubSpot.
Background
At HubSpot, our HBase clusters serve over 25 million requests per second at our daily peak traffic. We automatically run countless table descriptor modifications every day to maintain optimal performance. These modifications are necessary to facilitate maintenance like correcting inefficient table properties, tuning target region sizes as cluster sizes change, and coordinating HBase’s normalizer. HBase table descriptor modifications are one of the most fundamental admin operations, and, by default, they cause a totally unacceptable degree of downtime for our end users.
In this post I will explain how you can trivially configure two new settings in HBase to reduce — perhaps totally eliminate — downtime, latency, and user-facing errors induced by table descriptor modifications. First, I’ll proactively explain a few key terms.
Glossary
HBase
HBase is a distributed, scalable, big data store, modeled after Google's Bigtable. It's part of the Apache Hadoop ecosystem and designed to provide random, low-latency read/write access to huge datasets.
HBase Tables
Data in HBase is organized and accessed through tables, which consist of rows and columns. Each table is horizontally partitioned into regions, which are the basic building block for scalability and distribution. Tables have “Table Descriptors”, which dictate their configuration, specifying details such as compression type.
HBase Regions
A region is a subset of a table containing all the rows between a start key and an end key. As data grows, regions can be split and merged automatically to maintain system performance. Regions are distributed and managed across the servers in your cluster to distribute the read/write workload for your table.
99th Percentile Client-Side Latency
We measure the duration that each request to HBase takes from the client’s perspective. By taking the 99th percentile values of this histogram we are able to quickly understand the worst-case user experience with respect to product “slowness.”
Client Error Rates
We measure the volume of exceptions thrown by HBase clients at HubSpot. We monitor the number of exceptions divided by the total number of requests to get a quick sense for our system reliability from the HubSpot product perspective.
Table Descriptor Modifications
HBase allows the modification of existing table descriptors. Table descriptor modifications allow for the altering of table properties. These properties may include the table’s column families, compression type, data block encoding, target region size/count, normalizer configuration, and bloom filter configuration — just to name a few.
Descriptor Modification Downtime
HBase is a strongly consistent datastore by default. This means that there can be only one live copy of any given region at a time to eliminate the possibility for inconsistencies.
A table descriptor modification tells HBase that all regions for the given table must be “reopened” — moved from an OPEN state, to a CLOSED state, and back to an OPEN state — in order to apply the desired configuration changes. Because there is only one live copy of any given region, a region being in a non-OPEN state is effectively downtime for the region from the user’s perspective.
Until recently, HBase’s only behavior was to accept a table modification request and then attempt to reopen every region as quickly as possible. This expeditious pace sounds like a righteous goal, but we found that, in practice, it was disruptive for our user experience.
The Problem
Historically, our automation has executed all table modifications in the middle of the night. It does this to mitigate customer facing pain due to mass region re-opening. We found that, even in our quietest hours, descriptor modifications were still too disruptive. Two of our most important metrics for gauging user experience are 99th percentile client-side latency and client-side error rates. See the chart below where a table descriptor modification at approximately 1 am EST caused latency to spike from a few milliseconds to 30 seconds:
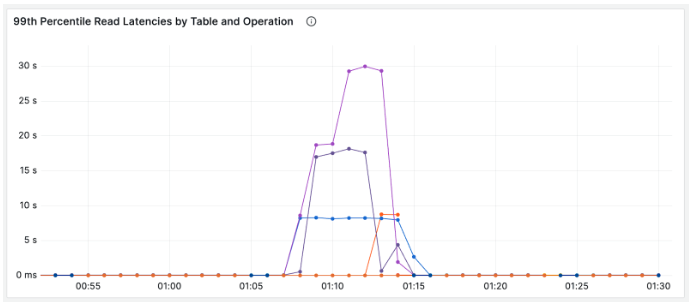
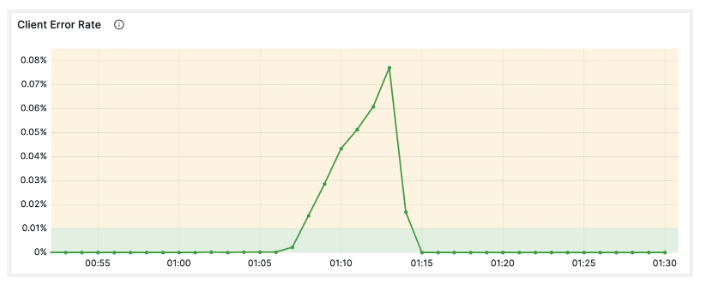
This elevated latency not only caused slowness for users, but also breached timeouts which caused client facing error volume to spike:
The Solution
Eliminating the downtime
I opened up HBASE-28215 which suggested that we could solve table descriptor modification induced downtime by throttling HBase’s ReopenTableRegionsProcedure — the ReopenTableRegionsProcedure being the operation kicked off as a result of any table modification. Again, the problem with the reopen procedure is that it kicks off sub-procedures to reopen each individual region, and it does so as quickly as possible which is too disruptive.
In the corresponding pull request we accomplished exactly what we sought out to do. We introduced two new configuration options:
Our configuration
We introduced the following customization to our HBase configurations at HubSpot:
With these configurations in place we ensure that we will cool down for at least one second between reopen batches, and we ensure that no batch will contain more than 50 regions.
We chose these initial values for a few reasons:
Accomplishing any given descriptor modification in no more than an hour felt like a reasonable starting point. With these initial configurations, we saw such compelling improvements that we have felt little need to iterate on these values.
Evidence of improvement
After applying the aforementioned changes we ran another table descriptor modification of the same table and at approximately the same time (1 am EST). It had no clear impact on 99th percentile latency:
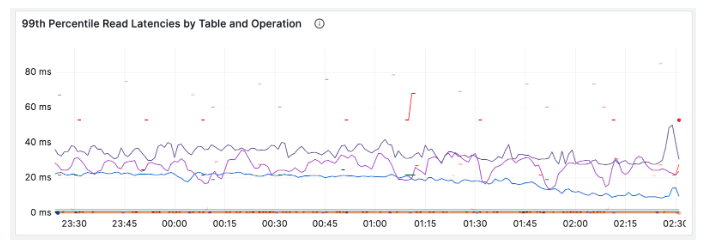
Similarly, the modification caused approximately zero additional runtime exceptions for HubSpot users:
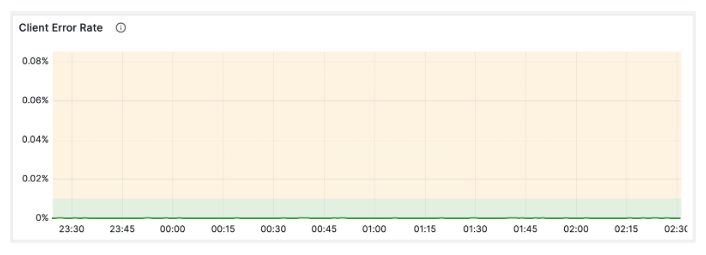
The sustained, lower volume, region reopenings are preferable to users because low server-side error volume can be hidden “under the hood.” This is possible due to the HBase client’s implicit retrying, and the retries' increased propensity for success due to the mild nature of the disruption.
A Bonus Suggestion
There are some very specific cases where reopening regions may not be necessary for your table modification. For example, if your change has no immediate effect on the composition of regions, or if you just don’t care whether your change is applied expeditiously. If you find yourself in this situation, then you can make use of a feature introduced in HBASE-25549: what we refer to as a “lazy table modification” at HubSpot. One can use this via the Admin interface like so:
As the release notes suggest, one should use this API with care because regions may be in an inconsistent state from when they are lazily modified to when they have all reopened.
Conclusion
By simply configuring both hbase.reopen.table.regions.progressive.batch.size.max and hbase.reopen.table.regions.progressive.batch.backoff.ms, you can turn a downtime inducing admin operation into a trivial one.
These features, plus “lazy table modifications”, and many more are available in HBase’s recent 2.6 release. Consider this your sign to begin an upgrade!
Are you an engineer ready to make an impact? Check out our careers page for your next opportunity! And to learn more about our culture, follow us on Instagram @HubSpotLife.