.png?width=1200&length=1200&name=kafka-consumer%20(2).png)
.png?width=1200&length=1200&name=kafka-consumer%20(1).png)
Kafka Night: Confluent and HubSpot on Real-Time Data Processing (Video)
Neha Narkhede is the co-founder and head of engineering at stream data platform company Confluent, and one of the original authors of Apache Kafka. ...
Written by Yash Tulsiani, Technical Lead @ HubSpot.
The HubSpot import system is responsible for ingesting hundreds of millions of spreadsheet rows per day. We translate and write this data into the HubSpot CRM. In this post, we will look at how we solved an edge case in our Kafka consumer that was leading to poor import performance for all HubSpot import users.
_________________
Background
Import is a tool for users to get their data into HubSpot from an external system. Let's begin by exploring how users typically model their data in an import file.

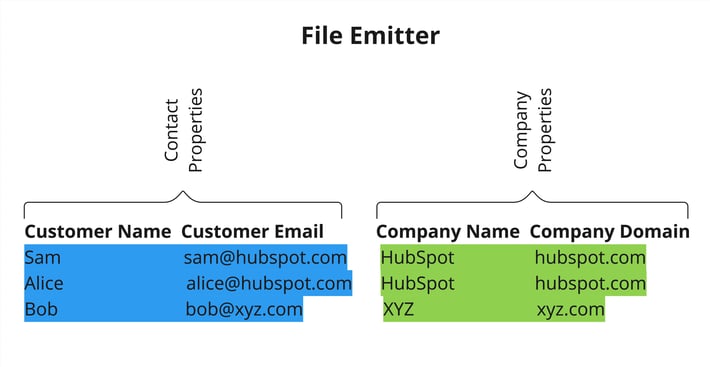
Example spreadsheet of contacts and associated companies. Both Sam and Alice are employees at HubSpot.
Each row in a spreadsheet maps to one or more objects and each column represents a property for the object. Each cell is the property’s value for the object in the row. As an example, in the sheet above we have two object types in a single row: a contact and a company object. The columns Customer Name and Customer Email are properties of the Contact object and the columns Company Name and Company Domain are properties of the Company object.
The objects in each row of the file are associated with each other. For example, Sam and Alice are employees of HubSpot. The desired outcome of this import is that we have a single HubSpot company record and both Sam and Alice are associated with that single company.
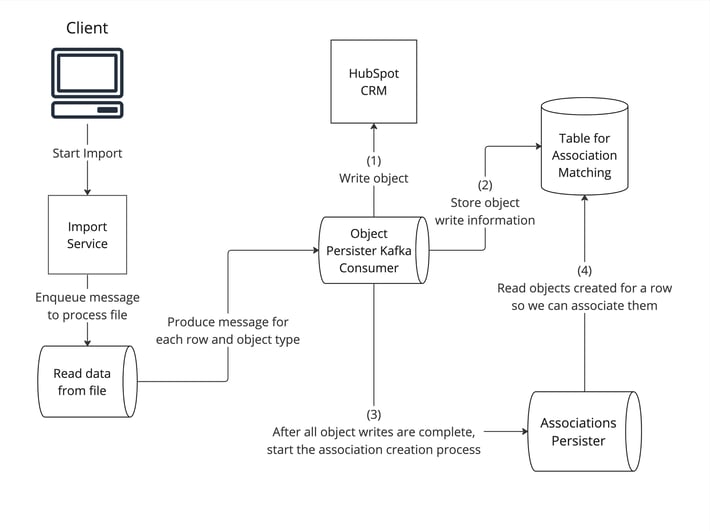 System diagram of the Import Pipeline
System diagram of the Import Pipeline
With that in mind, we can discuss the import pipeline at a high level. Initially, a user submits a request to process an import. We enqueue a message to a worker that reads the file and produces one kafka message per row and object type to the object persister worker. For the file shared above, we will have six Kafka messages produced to the Kafka topic. Three contact messages and three company messages.
Emitter publishes these six messages to Kafka.
The Kafka consumer performs the translation and persistence of each object. The consumer is also responsible for storing object metadata after writing the object to the HubSpot CRM. We use this metadata to write associations later in the import pipeline. This design allows us to parallelize all object writes, but we need to ensure we are not creating multiple objects of the same unique identifier when they are repeated in the import file. For example, in our file shared above, we do not want to have two HubSpot company objects.
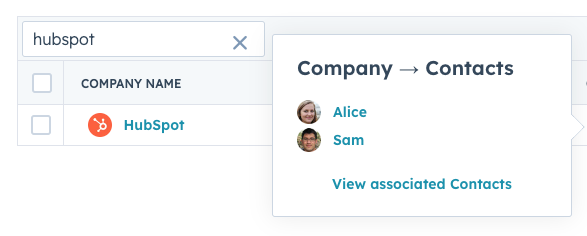
In the CRM, there is a single HubSpot company and both Alice and Sam are associated with it. In the import file, HubSpot is repeated in each row.
Preventing duplicate company writes
.jpg?width=682&height=193&name=Untitled%20-%20Messages%20(2).jpg)
Kafka messages are published which are later written to the CRM. There are duplicate write requests for the company HubSpot.
Within these Kafka messages, the domain hubspot.com is listed twice. If there is a delay between processing the two duplicate messages, we will correctly perform a no-op write for the second hubspot.com creation request. But, if these writes happen in quick succession to each other, we have the possibility of writing two companies with the same domain. Ideally, this issue can be avoided by atomicity guarantees within the downstream object write system. However, domains are treated as unique only within the context of import and not throughout HubSpot generally. This is because a CRM user might want to represent different organizations within a single company separately or keep subsidiaries of a single company separate.
On the other hand, imports will treat the domain as unique because we don’t have the option to individually ask the user on each conflict if they would prefer to create a new company or update the matching one. But even with atomicity guarantees, we would run into other issues. For object types that support atomic writes, parallel writes to the same object will cause lock contention and significantly reduce the throughput of the consumer.
Let's first see how we initially approached this problem, thought we solved it, but found out it wasn't sustainable as HubSpot scaled. To prevent accidentally creating two companies, we would send writes of the same domain to the same Kafka partition. By doing this, we know only one Kafka consumer instance will be processing messages for a given domain. The Kafka consumer would take out a local lock keyed by the domain to guarantee only a single write for the domain was happening at a given moment. Writes other than the duplicate domain would continue to happen in parallel, but if a single batch had the same domain repeated many times, those writes would happen sequentially.
.jpg?width=710&height=420&name=Untitled%20-%20Before%20-%20Normal%20(1).jpg)
Most messages are written in parallel, but the duplicate hubspot.com request is written after the first one is completed.
This design works fine when domains are repeated occasionally. In general, Kafka rows will be evenly distributed and each message in the Kafka batch will be written in parallel. However, if full batches of messages all had the same domain, each message in the batch would need to be handled sequentially. If we are processing an import with millions of repeated domains during a low traffic time, this can mean we will have a large series of batches that are processed slowly. This would bottleneck a single consumer instance causing uneven lag that could not be resolved by scaling and would significantly increase batch processing time for the unlucky partition.
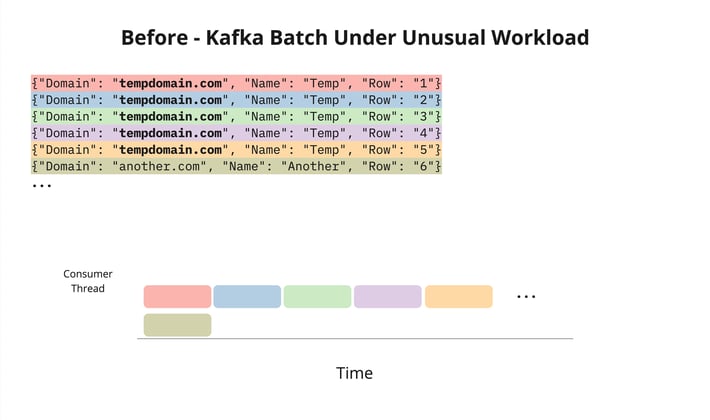
This innocuous set of messages slows down our worker significantly.
When this happened, we would have slowdowns across all imports in the data center until the bottleneck cleared. Eventually, we were getting paged for this issue at least once a week and each page required manual intervention. This increased our on-call workload, took away valuable engineering time, and resulted in unhappy customers. Not good!
Scaling by simplifying: Using a Bounded Set
When investigating solutions to this issue, one thing that was immediately apparent was that the vast majority of rows with repeated identifiers also had the same data for all columns of the object.
As an example, imports generally don’t look like this:

Two conflicting company names for the same domain.
They typically look like this:
All rows of hubspot.com have the same company name.
After noticing this pattern, we decided that if two objects have the same unique identifier, then it would be reasonable to assume that they have the same data all around. This means we would only need to send a single write request for this company and never again. Let’s discuss how we accomplished this.
While parsing the file and producing messages to our Kafka workers, we can store the row’s domain in an in-memory set. If we encounter a row that has the same domain as a previously seen row, we know we can skip the company write. Even though we skip the company write, we still need to write the association between the row’s contact and the original company. Unfortunately, at the point we determine we have a repeated company, we do not have enough information to write the association. Writing the association requires us to have the HubSpot CRM generated ID that is created upon object write. At the time the emitter detects a repeated company, we are not guaranteed Kafka has completed the write for the original company. To address this issue and to maximize parallelization, Kafka should continue to handle this work but with the information that this is a repeated object.
In our reworked Kafka consumer we initially ignore these tagged messages and perform writes for the untagged messages. After all the untagged messages in a batch have been written, we are guaranteed that all the tagged messages have a relevant object within the CRM. The objects for tagged messages were created either in this batch or in a prior batch. With that guarantee, we can perform lookups to get the relevant IDs and directly write them to the object metadata table. After this, the import pipeline can create associations with no special handling for these rows..jpg?width=710&height=420&name=Untitled%20-%20Today%20-%20Unusual%20(1).jpg)
After all the untagged messages are written, we can write the metadata for the tagged messages without performing a duplicate object write.
This solution has been great for us. It has completely removed the bottleneck in our Kafka consumer without negatively impacting our emitter’s throughput or memory footprint. One critical aspect that allowed us to do this was using a small bounded set for our identifier lookup. Using a small set means that lookups are fast and memory usage remains low. For some rough math, the average domain is 12 characters or 24 bytes. If we store the 1,000 last-seen domains, that's still only 24 kilobytes. We would need 42 imports running for 1 megabyte of data. Even when we have thousands of imports emitting on a single instance, we do not need to be concerned about memory.
Using a small bounded set means we can have false negatives for repeated identifiers, but as long as the bounded set size is larger than the Kafka batch size, we will not have any increased batch processing time in our consumer. Each untagged message in a Kafka batch is guaranteed to be for a unique domain. So, even though we will occasionally perform no-op writes for some repeated domains, it will be less frequent than before and it will not cause any lock contention.
-1.jpg?width=710&height=773&name=Untitled%20-%20Frame%203%20(1)-1.jpg)
We have a false negative for row 8 because abc.com was evicted. This is okay and we will still avoid write lock contention as long as the identifier set size is larger than the Kafka batch size.
In our current solution, we are still sending messages of the same unique identifier to the same partition. Unlike before, just the first message will be written, but we are still producing to partitions unevenly. Fortunately, our consumer will not experience elevated latency even when we have millions of repeated unique identifiers. In the consumer, we deduplicate repeated identifiers for the tagged messages and perform one read per unique identifier in the batch rather than one read per tagged message. So, if we have a large series of problematic batches, we are performing a single read and single HBase write for each Kafka batch. This allows us to very quickly process all the extra messages in the given partition.
.png?width=1859&height=649&name=18c7566b-ee3d-4d02-9bd5-cec5881697f7%20(1).png)
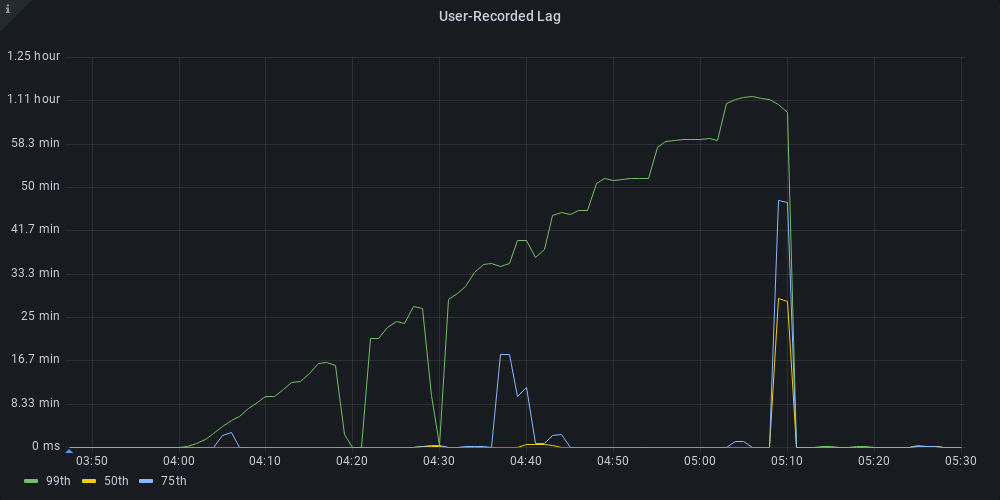
This is an example of the Kafka delta for a single problematic import running on a single consumer instance. The left side half shows what this import looks like today and the right side shows how this looked before our changes.
Impact and Conclusion
On an edge case import of 500,000 rows with repeated emails and domains we reduced the time to finish the import from several hours to under 10 minutes. More critically we eliminated the bottleneck for other customers so they no longer needed to wait several hours for this edge case import to finish. With our solution, we are breaking the extremely uncommon use case of an import having conflicting values for a unique identifier but in return, we are improving the system for the vast majority of our customers and their more common use cases.
As a product grows, we build features based on information and assumptions about our customers at that time. It's important to think critically about these prior assumptions and if they make sense as we gain more information. With scale, we need to keep in mind the balance between increasing the complexity of our system and rethinking prior business decisions. By watching out for these uncommon use cases, we can remove complexity from existing systems because ultimately, simple systems scale better.
Are you an engineer ready to make an impact? Check out our careers page for your next opportunity! And to learn more about our culture, follow us on Instagram @HubSpotLife.