Understanding Thread Dumps
Your application slows down suddenly or maybe it just stops doing anything. What do you do? What can you do? Well, you can take a thread dump. In the ...
HubSpot has use cases where many threads in a single process need to coordinate to find the most frequent items in a high cardinality data stream. In this blog post, we describe our design for doing this in a way that is fast, thread-safe, and memory efficient.
The web services in HubSpot’s backend all run with a large number of threads for concurrently handling many HTTP requests. A majority of the workloads we handle are I/O bound, so running our web services with a large number of threads is usually necessary to get full CPU utilization.
For years, one problem our web services frequently encountered was receiving a large number of concurrent requests that each required us to fetch the same row from the backing database. This sort of access pattern can degrade the performance of our APIs, since all of those requests go to the same node of the backing database, potentially overloading it. This is described in much more detail in our last blog post. We call this scenario hotspotting, and it can make the experience for our users slow and unreliable. When this happens, in order to mitigate the problem, we need the ability to track which rows are being frequently accessed. In other words, we need to know which rows are “hot”.
We’ll first walk through what a simple, naive design for a hotspot tracking system might look like. We’ll discuss why that approach doesn’t work, then we’ll iterate on the design and make improvements until we arrive at a place where our design is fast, thread-safe, and memory efficient. If you work on concurrent programming, especially in Java, hopefully this sparks your imagination and gives you ideas you can apply in the future.
Naive Approach
Let’s say we have a web service where callers make HTTP requests to fetch some resource, and each resource is uniquely identified by a string. To handle an HTTP request asking for resource XYZ, we do two things:
For step 1, we’ll have one HotspotTracker object per instance of our web service. This singleton HotspotTracker will be shared across all HTTP request threads in the process. A naive implementation might look something like this:
For brevity, it’s not shown here, but a background thread would run every minute and do the following:
This once-per-minute report of hot IDs could be logged for an engineer to look at later, or it could also be exposed to other parts of the application so we can apply special treatment for hot IDs (like here).
If you’re familiar with concurrent programming in Java, you know the above design doesn’t work because HashMap is not thread-safe. Concurrently running HTTP requests need to safely share this HotSpotTracker, so we need to use a thread-safe data structure. A more correct implementation might look something like this:
ConcurrentHashMap and AtomicLong are thread-safe, so this design is better, but there’s one major flaw with this approach. The memory usage of this class is unbounded. Even though we’re clearing out the countsById map every minute, each instance of our web service can receive many thousands of requests per second, and each of those requests could be providing different IDs than the other requests. Over the course of one minute, the map could accumulate a huge number of entries, and if the ID strings are large, our process could easily run out of memory. We need a way to track hot IDs using a finite amount of memory.
StreamSummary
In order to limit the memory usage of the HotSpotTracker, we’re going to replace our countsById map with a StreamSummary.
StreamSummary is a data structure that comes from a popular open source project called stream-lib. It's based on the algorithm proposed in this paper, and it fits our use case perfectly. As stated in the paper, StreamSummary "is space efficient and reports both top-k and frequent elements with tight guarantees on errors".
Similar to probabilistic data structures like HyperLogLogs, StreamSummary is a data structure that allows us to significantly reduce our memory use by only approximating the counts for hot IDs. Storing an exact count for each ID requires using an amount of memory proportional to the number of unique IDs. But by allowing approximate (but still very close) counts for hot IDs instead of exact counts for all IDs, we can set an upper bound on our memory use. So now our design might look like this:
Now we’ve solved our unbounded memory usage. But unfortunately in doing so, we’ve introduced another problem. StreamSummary is not thread-safe, so similar to the very first design proposed in this blog post, this design is broken. If we look into the internal implementation details of StreamSummary, we’ll see it manages state using non-thread-safe classes like HashMap. stream-lib does provide a thread-safe class called ConcurrentStreamSummary with a similar interface. However, the implementation is very different, and its performance was not adequate, so we can’t use it. We need to find a way to safely share this non-thread-safe StreamSummary across multiple HTTP request threads.
One naive way of making shared access to StreamSummary safe would be to synchronize all access to it:
Multiple threads can safely share non-thread-safe code if we synchronize all access to that code. So now our program is both memory efficient and thread safe.
So are we done? Not yet. The synchronized keyword causes each thread calling the track method to acquire a lock on the HotspotTracker object before executing it, so our program is now much slower than it was before. Our web services handle many HTTP requests concurrently in order to take advantage of the multicore processors that they run on. By synchronizing all access to the HotspotTracker, we would be adding a single point of contention to our otherwise highly parallelized process, and performance would suffer.
Queues
These sorts of problems are often solved by using in-memory queues. Instead of having all our HTTP request threads directly adding items to the StreamSummary, they can place items onto a shared in-memory queue, and then a single background thread can continuously consume items off of the queue and update the StreamSummary:
For the sake of brevity, we’re omitting the code that spins up the background thread that consumes items off of the queue. In this post, we’ll just focus on the code pushing items onto the queue. Visually, this design looks something like this:
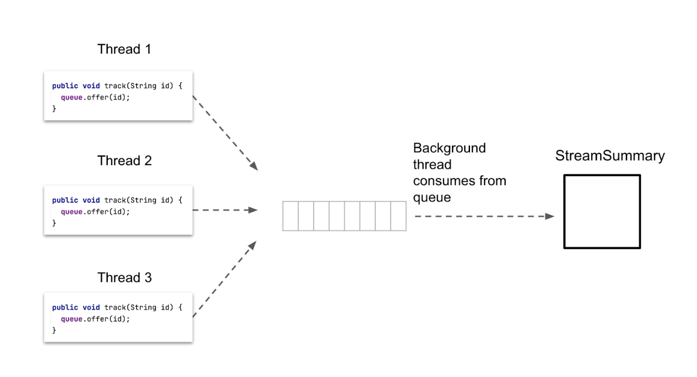
In this design, because there’s only a single thread updating the StreamSummary, it’s okay that StreamSummary is not thread-safe.
A benefit of using ConcurrentLinkedQueue as our queue implementation is that it uses a lock-free algorithm for pushing items onto the queue. So even if multiple threads are adding items onto the queue concurrently, there is minimal contention, and the program is fast. Unfortunately, ConcurrentLinkedQueue has one major drawback. It’s unbounded, and there’s no constant-time way to ask for the current size of the queue, so if our HTTP request threads add items to the queue faster than our background thread can process them, the queue will grow indefinitely, and our process will run out of memory.
We need a bounded queue instead, and the Java platform has just that. Instead of ConcurrentLinkedQueue, we can use an ArrayBlockingQueue:
Now, if the thread consuming items off of the queue can’t keep up, the queue won’t grow indefinitely. If the queue is already full, our HTTP request threads will just fail to add items to the queue, and we won’t track that request. In that case, we lose some accuracy in our hotspot tracking, but that’s significantly better than running out of memory and crashing the process.
Our program is now thread-safe and memory efficient, but once again, we’ve made our program slow. ArrayBlockingQueue is implemented in a way where threads need to acquire a lock on the queue before placing items onto it. So similar to the earlier approach where we synchronized all access to the StreamSummary, we’ve introduced a single point of contention that will reduce the parallelism that our program can run with, and performance will suffer.
We need HotspotTracker to be fast, thread-safe, and memory efficient. In all of the designs so far, we’ve only met at most two of those three requirements. To meet all three requirements, we’ll need some help from outside of the standard Java platform.
Final Design
Our problem with the standard queues from the Java platform is that they are either bounded or lock-free, but not both. Luckily there exists a silver bullet for this problem, the LMAX Disruptor. This popular open source library provides us with exactly what we need: a bounded queue with lock-free enqueues. As described in their technical paper, because it doesn’t use locks, the LMAX Disruptor is significantly faster than ArrayBlockingQueue, and this makes it an extremely useful tool for building high performance, concurrent applications.
Swapping out the ArrayBlockingQueue for an LMAX Disruptor, our design now looks like this:
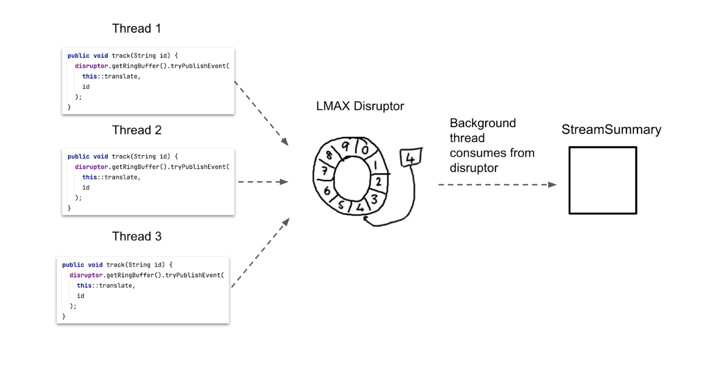
Unlike standard queues from the Java platform, the LMAX Disruptor has a somewhat confusing API. Using it involves a lot of boilerplate, so we’ve omitted most of the code in this post. However, conceptually you can think of it as being just like an ArrayBlockingQueue, only faster.
Conclusion
This is our final design for the HotspotTracker. It is fast, thread-safe, and memory efficient. If you’re interested in reading an example of how we’ve used this library to improve the reliability of our databases, check out our blog post on Preventing Hotspotting with Client-side Request Deduplication.
Introducing concurrency can lead to significant performance improvements in our applications, but as we’ve seen in this blog post, it also forces us to think carefully about problems like thread-safety and lock contention. If you work with Java and this is something you’d like to learn more about, Java Concurrency In Practice is a great introduction to the subject.
Interested in learning more about #HubSpotLife? Check out our careers page and follow us on Instagram @HubSpotLife.