Our Journey to Multi-Region: Supporting Cross-Region Kafka Messaging
This is the last installment of a five-part series about HubSpot’s year-long project to rework our platform for multi-region support. Check out the ...
In this post, we will explore HubSpot's strategy for managing global data with MySql. This is the fourth installment of a five-part series about HubSpot’s year-long project to rework our platform for multi-region support. Check out the introduction to the series here.
“So, you’re saying you’d like just these three tables to have the same data in every database, but you’d like to write different data in the tables alongside them and join that all together in different datacenters? Got it. That’s odd. I wouldn’t have expected that.”
“I see, it’s not just you, it’s actually half the engineering teams. Let me get back to you.”
Many data infrastructure teams have their own special homegrown way of keeping distributed data sets accurate and in sync. If you’re like me, your first experience of it was setting up that first non-trivial replication scheme to keep a travel review web site and reporting database in sync while also allowing content teams to make changes without bringing the whole thing to a halt. Or perhaps your experience was from more of an Enterprise background, working with something fancy like Change Data Capture, Event Sourcing and CQRS. No matter your background, or reason for joining the Replication Club, these types of systems have a common set of problems and edge cases to solve. They often appear very simple at first but have a beautiful amount of nuance and complexity under the surface. This is how we recently solved this problem at HubSpot across 1200 MySql installations in two data centers and our solutions to the common problems. Hopefully our experience may provide some helpful insight if you’re about to embark on a similar journey.
As we started to talk to engineering teams about Hublets and the technical approach, we began uncovering use-cases that fell outside of the happy path.For example, HubSpot maintains an app marketplace where 3rd party integrators can use our public API to create apps, update app metadata, or delete apps. The multi-region project introduces a new challenge here, which is that by default each Hublet would get a totally separate marketplace API and marketplace database. But this isn't what we want; our customers and our integrators expect a single, global marketplace. Once integrators hit our API to create an app, it should be available to install in any Hublet. This is directly at odds with our design goal of each Hublet being isolated and not communicating with each other.
We ended up finding a few dozen use-cases like this, which we colloquially referred to as "global data". The simplest solution to this problem is to direct all reads and writes to a central database in North America. This works at a basic level, but it means that every read from Europe needs to cross the Atlantic ocean, which is slow and unreliable. At this point, we started digging more into the details of each use-case so that we have the right context to evaluate trade-offs. What we found is that these global data use-cases:
Based on this, the design we settled on is to direct all writes to a central database in North America, and then replicate those writes to all other Hublets asynchronously. This way, each Hublet can do local reads, which improves performance and reliability.
As I hinted earlier, our solution is relatively simple on the surface. We use a MySql configuration parameter called replicate-do-table which, when set on a replica, will only apply changes for a given table. We designate the database in North America as the primary and use native replication along with this flag to keep the other datacenters up to date. In our case, we don’t make a direct replication connection between data centers and instead use a cross-account S3 bucket to distribute binary logs. We did this to keep isolation between the clusters; keeping every data center up to date with the current primary in North America was going to be error-prone and complex. It also allowed us to layer extra functionality on top of our stream that I describe below.
Creating those filtered binary logs in North America is a matter of standing up a replicate-do-table configured mini-replica with a cron job that does the uploading. We call this replica the “binlog processor”. The binary logs get timestamped, md5’d and compressed, and uploaded alongside a well known “meta index” file that tracks the order of uploaded files. After filtering, the binary logs are pretty small and compress well. Applying those binary logs in other data centers is just another cron job that grabs the latest meta index and applies files that haven’t been applied using mysqlbinlog. That’s basically it!
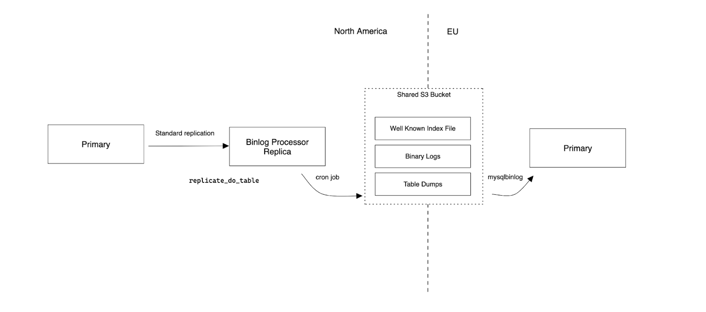
MySql replication already has some built in features to deal with many problem areas such as duplicate transactions when run with GTIDs. Even if we need to recover a binlog processor and duplicate transactions end up getting uploaded, MySql will handle those gracefully on the destination. Still, problems such as missing files, replication bugs and unintended writes on the destination tables can occur. Our strategy for dealing with these problems is to allow the destinations to request a table dump to be performed at the source through a cross-data center HTTP request. This works because the tables are small enough to be dumped in a short time window.
Mechanically, the table dump ends up being another special type of entry in our meta index. To take it, we pause replication, flush binary logs and lock tables before running plain old mysqldump. This allows the destination to continue the replication stream immediately after the dump and also allows other non-errored destinations to skip the dump if they don’t need it. We manipulate the logical dump to have it perform the restore in a shadow table and then atomically RENAME the newly populated table into place. There’s also some interesting stuff we do with GTID comparisons to ensure destinations don’t go backwards in time when restoring a dump and deduplicate multiple unprocessed dump requests.
A not so great side effect of this is that it does stop the flow of data into other data centers while the dump is happening. Other companies have solved this in a more complex way: Netflix in particular has a very detailed series on how they did it, and Debezium has another battle tested implementation. In our case, at least right now, we allow for a temporary spike in data freshness.
MySql replication also helps us with supporting basic schema migrations out of the box. ALTER TABLE statements are applied as they’re encountered in the replication stream. Of course, some statements are more benign than others. You’ve probably had that nervous feeling when running an innocent looking ALTER statement on a large table that didn’t return as quickly as you wanted. Suddenly CPU and I/O alerts start to fire that you didn’t know existed, and no user is able to run a query. We have too. That’s why we use gh-ost to perform most of our migrations online. It’s a fantastic tool. If you haven’t used it before, it works by creating a shadow copy of the table with the intended schema change already applied and performs simultaneous writing and backfilling before a “cutover” step where the newly schema-ed table is dropped into place.
In order to support this type of migration, we needed to allow tables that followed the gh-ost naming convention to also replicate so we could ensure the same operations were performed in the destinations. Additionally, we had to redefine what the word “cutover” meant for global tables since this would require a certain application-level backwards compatibility to be in place in all datacenters until the migration was complete. We enforced this in our tooling instead of attempting to bake the concept of a migration into the existing stream.
Interestingly enough, gh-ost migrations on tables with DEFAULT CURRENT_TIMESTAMP columns have been the primary reason we’ve needed to run table dumps at all because of a bug in mysqlbinlog that breaks the replication scheme when gh-ost starts up a migration.
Our final frontier was figuring out how to handle adding and removing tables from an existing replication stream. Again, this seems simple upfront – we could just add it to the replicate-do-table list before using the CREATE TABLE statement and everything should flow through as intended. Most of the time, it turns out, the tables already existed and we needed a plan for that.
This is what we ended up with:
This system has been happily operating for over a year and seen wide adoption across the organization. Because we kept the moving parts relatively decoupled and encoded as much state as possible within the stream itself, we haven’t had a lot of complicated maneuvers to perform around upgrade paths and cross-service dependencies. The biggest problems we’ve faced to date have mostly been around table growth, which impacts how quickly we can restore freshness. We’re working on some ideas there and hope to share them as we implement them.
Stay tuned for the final installment in the "Our Journey to Multi-Region" series where we're sharing HubSpot's solution for cross-Hublet Kafka topic aggregation and deaggregation.
Other multi-region blog posts:
If this sounds like the type of problem you’re interested in solving at scale, we're hiring! Check out our open positions and apply today.