Saving Millions on Logging: Delivering Savings
In tech companies, Cost of Goods Sold is a key business metric driven in large part by the efficiency of software architectures. Saving money always ...
The other night, I was out having dinner with a former colleague of mine. We were catching up and trading war stories, and naturally my new role at HubSpot came up. Having experience building delivery pipelines in the past with off-the-shelf software, they asked me about what kind of software HubSpot uses to manage its delivery pipelines.
Jonathan Haber gave a great tech talk back in 2015 about the challenges we had with Jenkins, (The talk begins at 37:50 but Jake Ouellette’s talk on builds is awesome too!) so it might not surprise some regular readers of this blog that HubSpot created its own build platform which we call Blazar and our own deploy system called Orion. Having homegrown delivery tooling has a lot of advantages, and ours in particular solve a lot of challenges that existing systems have at scale, and allows us to do things that would be difficult or impossible with a plugin model. Let’s dig into some of those specifics.
Philosophy
At HubSpot, while we empower teams to be independent decision makers on which technology they choose, we strongly push teams towards using “Standard Stack” for a number of advantages that have enabled us to scale.
Our CI/CD (continuous integration, continuous deployment) software is no exception to this:
Build Pipeline Definition
Like any build system, Blazar is essentially an orchestrator of executing build tasks which are defined via configuration files we call “buildpacks”. Buildpacks are great because they allow teams to manage and tweak existing build configurations, and create definitions for up-and-coming technologies we are looking at adopting, such as TypeScript.
A buildpack might look something like this:
So any given technology we use (Java, React, Python to name just a few) will have a buildpack for building it, and all builds on that stack are then built in the same way. There are very few exceptions to this. If we think we have found an exception, we try to find a way to improve the existing pipeline. There are other features not shown here which you would expect in any given build system, such as only publishing on a default git branch, or publishing a branch to a test label. Build definitions here are similar to modern day CI/CD systems.
Our build system Blazar automatically discovers deployable modules (java, node package definitions) when they are added to a repository and builds them. Very little configuration is needed. All you need to do is tell Blazar that a repository is buildable, and it will:
For all of this capability, our config file is incredibly simple:
Making our tooling opinionated allows us to deliver this simplicity and build and deploy any new project incredibly quickly.
Deployment
Once a build is made available, our deploy system, Orion, kicks in, deploying around 50,000 times per day across 3 data centers. Orion has been designed to scale with HubSpot (we’ve come a long way since 2013) . It’s made up of different components, each built on the same standard HubSpot stack that powers HubSpot itself, which allow us to achieve this:
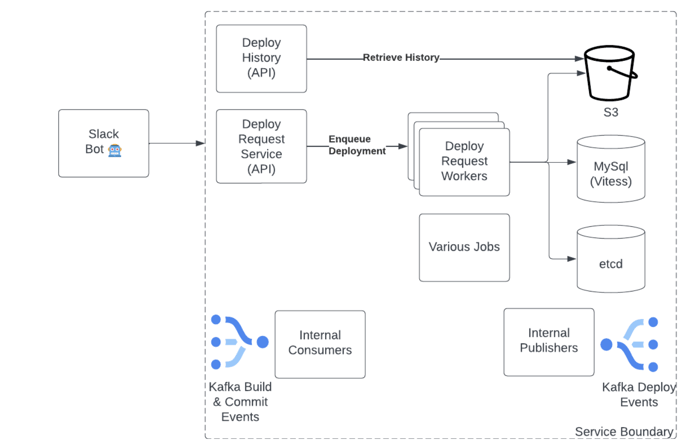
A few of the core components that make up Orion, the HubSpot deploy system
As an example, just this past week we released a library update that was used throughout most of HubSpot’s services, and were running about 800 simultaneous deployments on just 5 deployment workers.
Our deploy platform will automatically release builds to our test environment. From there we will run acceptance tests with options to automatically revert to the previous build if the tests fail.
Our deploy system is entirely built in Java. Changes to our deploy behavior usually involve a pull request, and then a re-deploy of our system. Interestingly, our deploy system is distributed enough that it actually deploys itself.
What’s wonderful about this type of solution is that we gain access to the extensive test tooling that Java offers. Any change in behavior to our deployer can be unit tested, integration tested, and acceptance tested before it’s made available in production. This is typically much harder to do in an orchestrated execution environment. Additionally, we have separate instances of our deploy system deployed to handle either test or production deployments. This gives us further safety by allowing us to test deployment behavior changes just against our test environment, and roll back if needed.
Being tightly integrated with our own platform-as-a-service, we are also able to allow engineers and product managers to individually test changes before a pull request is merged in. The reviewer simply clicks on a link that our bot posts, and our load balancer will route their traffic to a provisionally deployed instance of the service that’s only accessible to that reviewer. We use cookie-based routing to allow the user to test this specific instance and everyone else is using the normal test environment.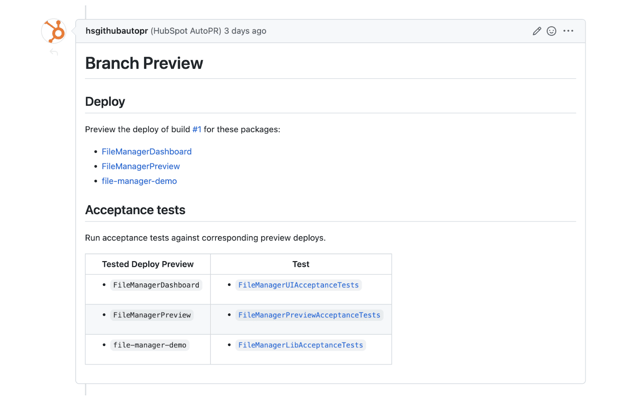
Image of the HubSpot Bot posting a link in a pull request which will enable a deployed build of the branch for the reviewer to preview.
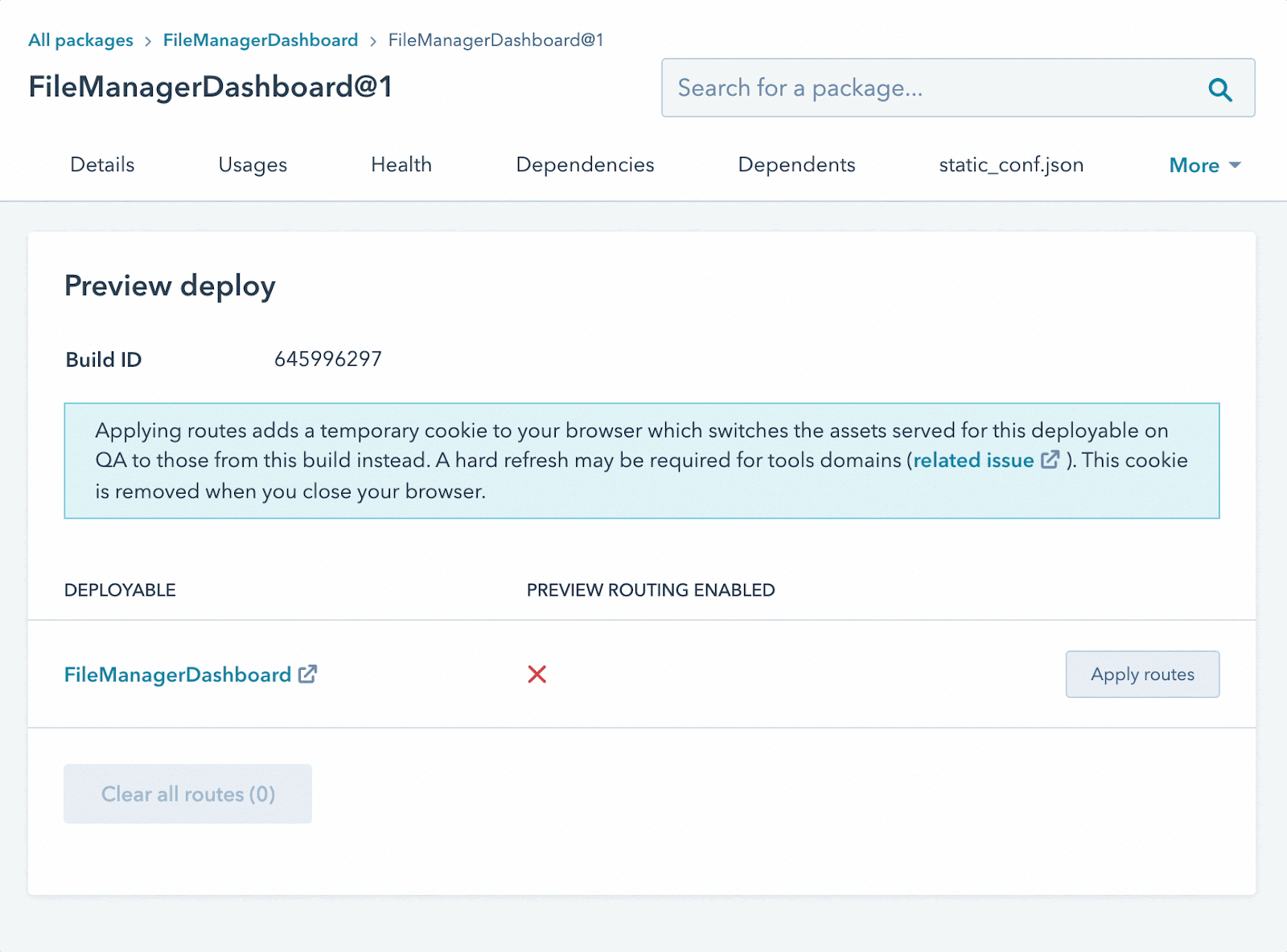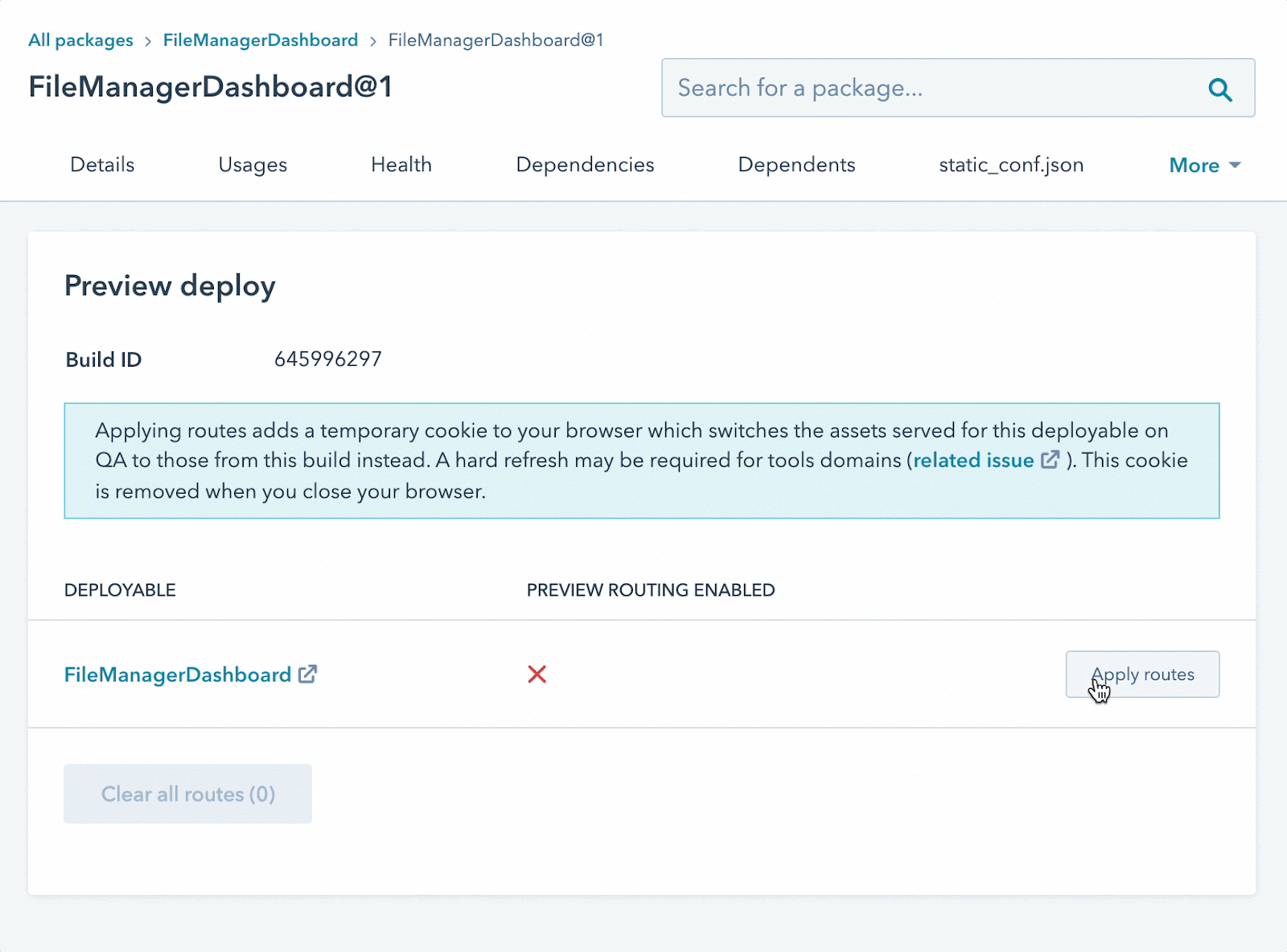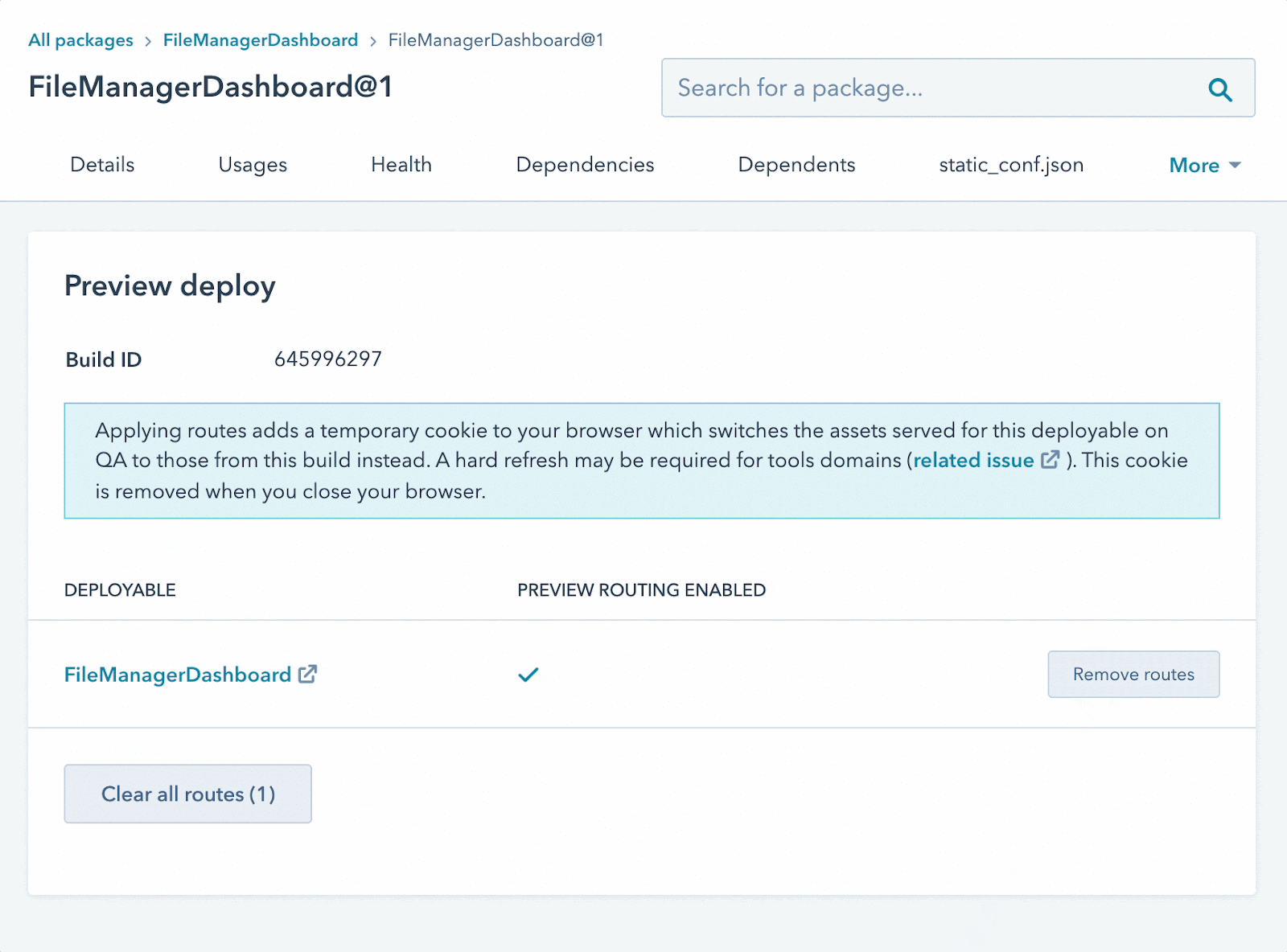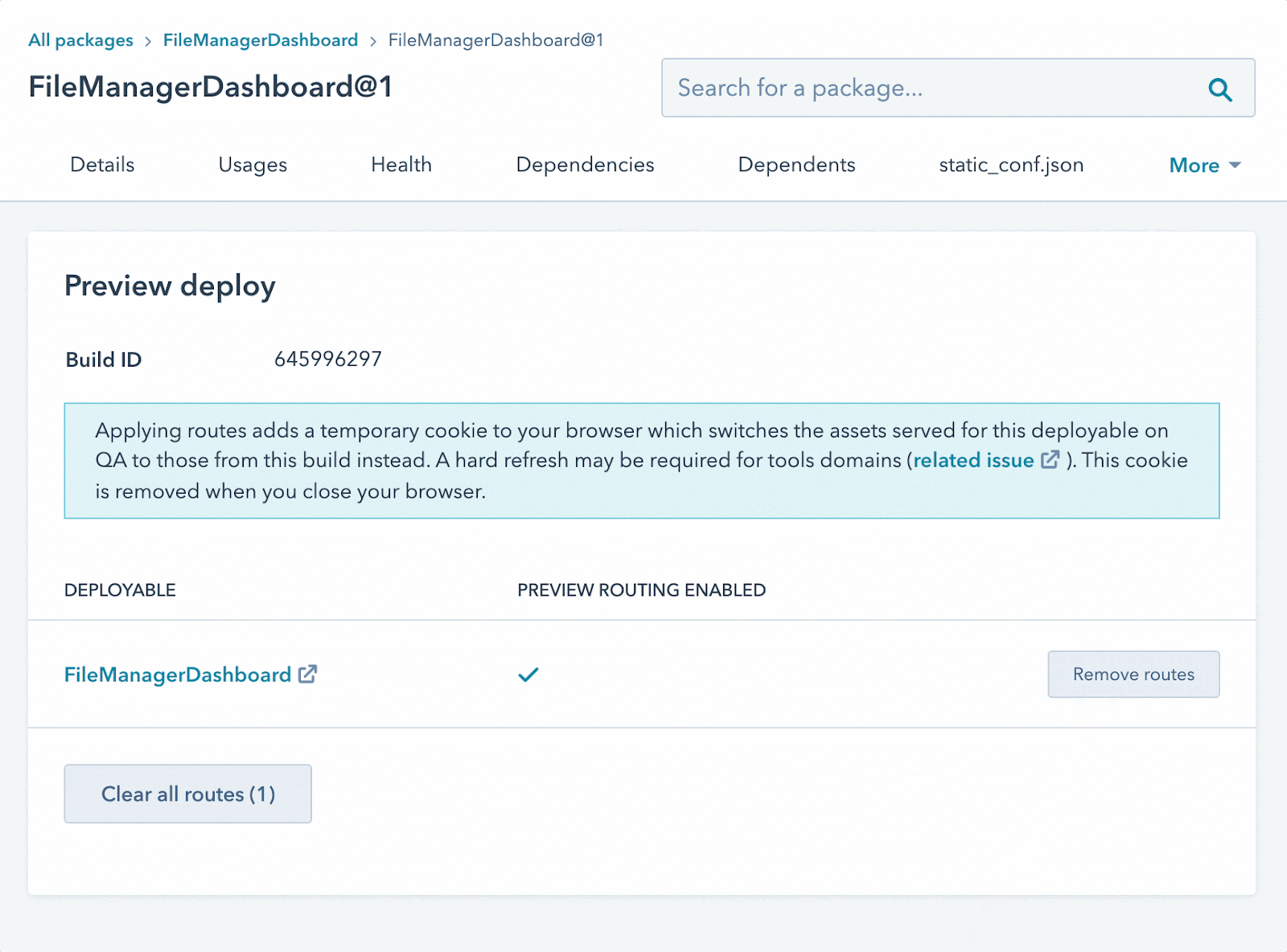
Animated gif of the interface where the engineer will enable and disable their branch preview. Instructions on how to remove the route after completion.
Yeah, it’s pretty awesome.
When evaluating off-the-shelf CI/CD tooling, a lot of these features are possible. After all, CI/CD tools are mostly just execution-orchestration engines that do whatever you tell them to. Being able to control the orchestrator itself delivers incredible benefits.
Consider how you might test a change to your deploy script. While modern CD systems allow for git-managed YAML and branches, they can typically only be truly tested by finding a project to deploy and trying to run an actual deployment. It’s much nicer to be able to test out these changes with JUnit and mocks.
Consider also deployment triggers – something that decides whether or not to initiate a deployment. Most CD systems have them, and they will initiate a deployment after a successful build, or a commit to the default branch.
Our triggers are contextually aware of what else is deployed and can use that context to be able to decide to execute or not. For example, our deployments to our test environment won’t blow away a feature branch that’s currently deployed just because a new default branch build is available. We also won’t trigger a deployment to prod if it’s after the team’s working hours.
To achieve this same behavior in an off-the-shelf CD system, you might need to write a script that checks its own history via some API the CD system exposes, or perform some other lookups as initial build step, but you’d also have to fail the build. This would lead to a string of failed deployments in your history, which are “as-intended” behavior and might mask actual failed deployments.
Here’s a list of some other unique features to HubSpot’s CD platform:
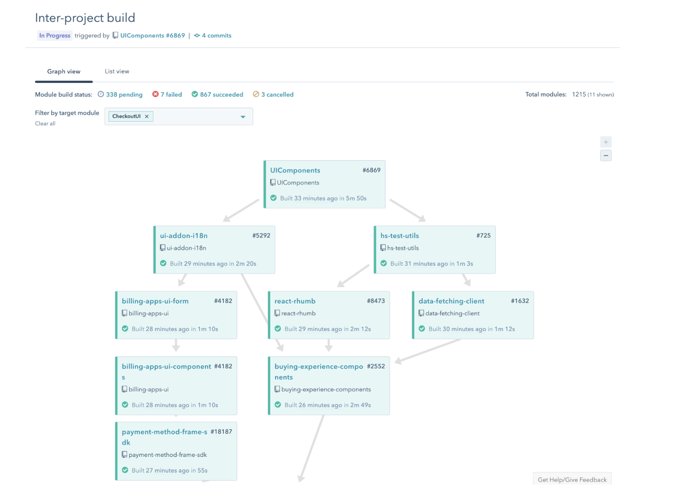
An image of a dependency graph showing how a build of UI Components triggers an additional 1,215 builds downstream and the order in which they occur.
Bad Builds: if you own a library, you may have at one point released a version that breaks things. Our evergreen approach somewhat negates this by allowing us to roll-forward/backward with ease, but our engineers can mark these builds as bad which will (a) prevent our deploy system from rolling it out, and because our deploy system tracks what is deployed at the dependency level, we can also (b) notify our engineers to roll back any deployments that already went out which included this bad build.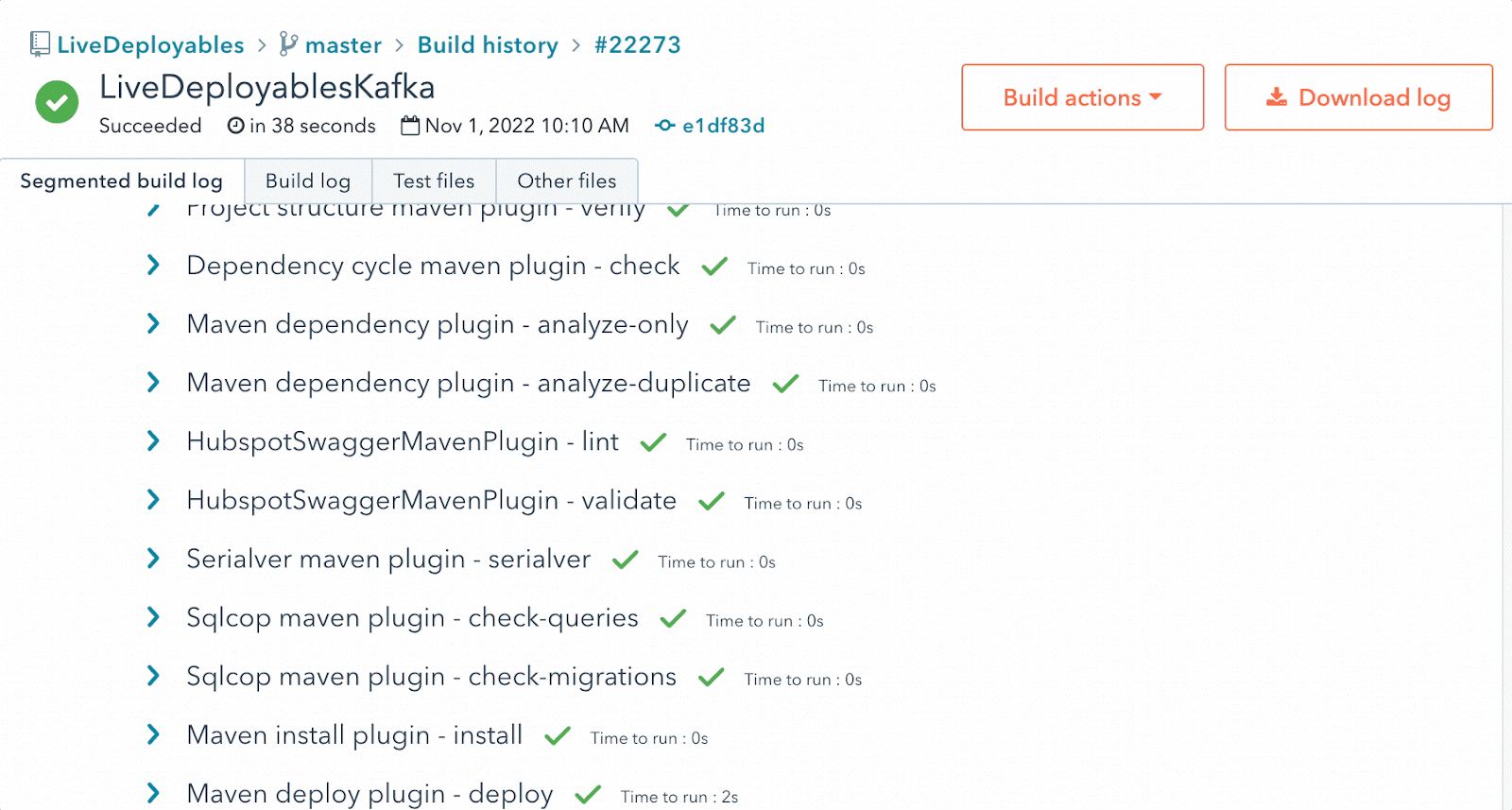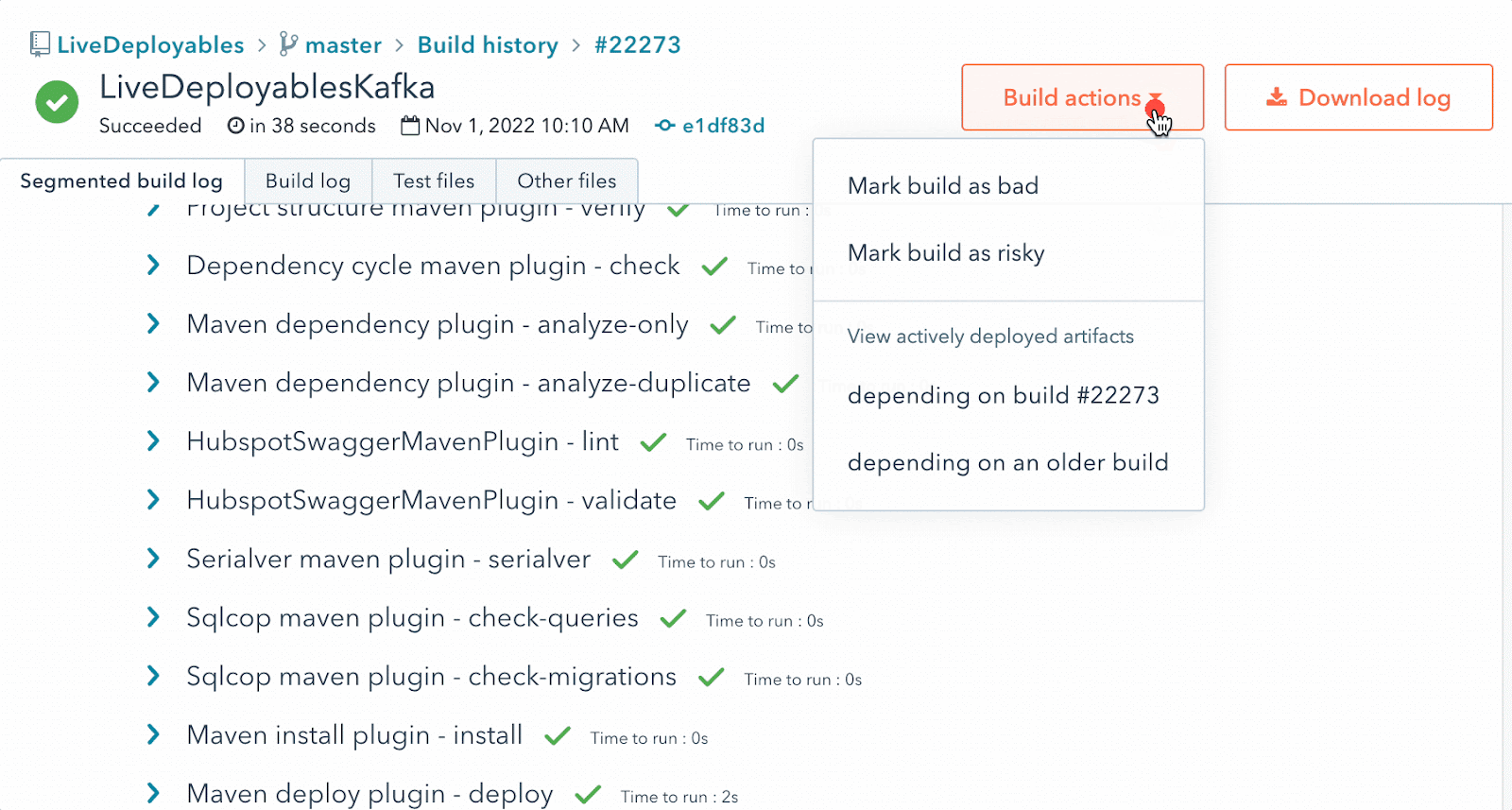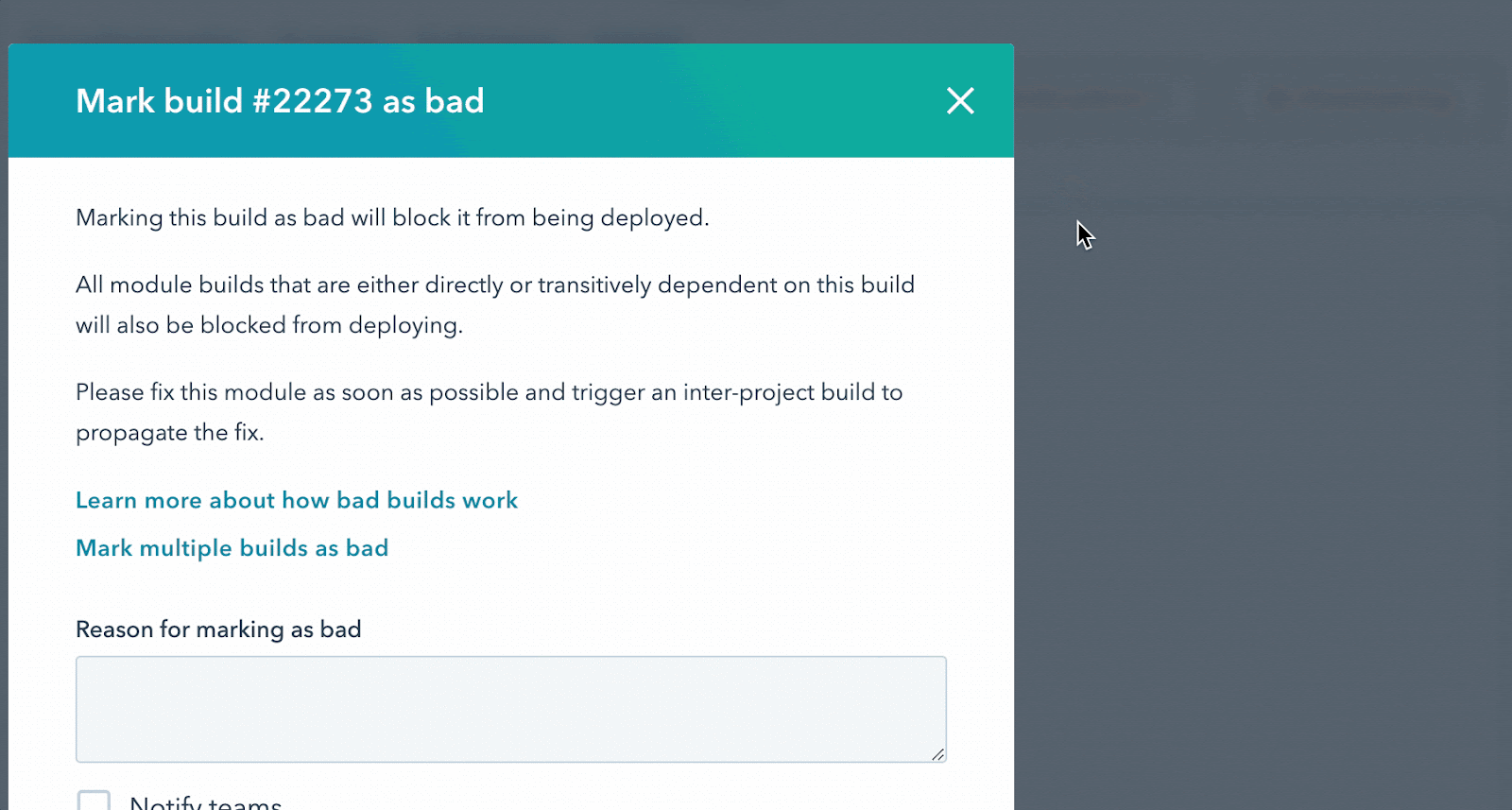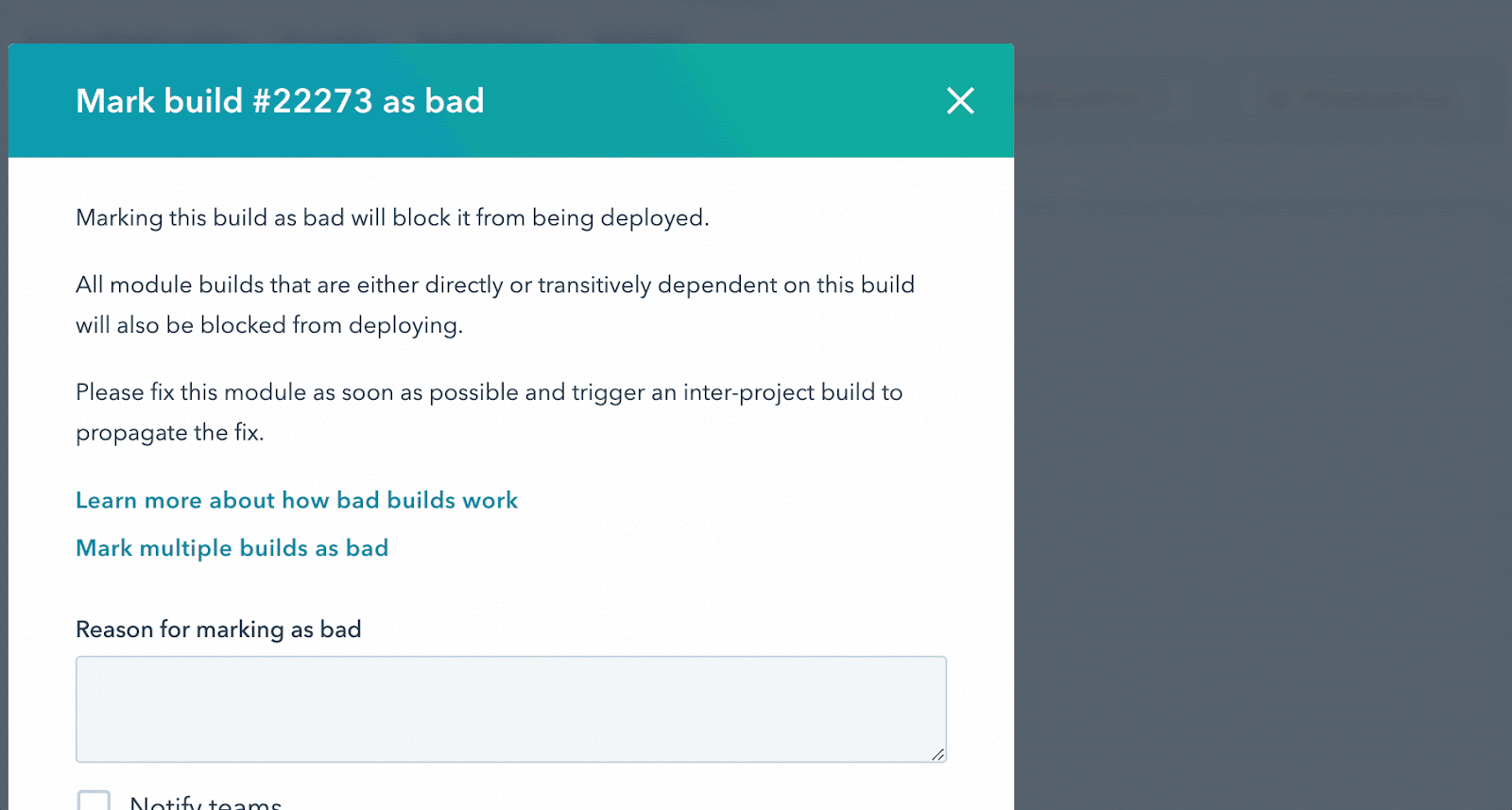
An image of an action menu to mark a build as bad, with an option to notify teams.
All of this flexibility makes it really fun to work on software at HubSpot. As an infrastructure engineer, I get the opportunity to have a direct impact on every engineer who pushes code out the door, without constraints of existing tooling.
Is there something that you’d like to learn more about how we build and deliver software at HubSpot? I’m looking for ideas on future continuous delivery blog content. Drop me a message on Twitter or LinkedIn and let me know what you’d like to see!
Interested in working on challenging projects like this? Check out our careers page for your next opportunity! And to learn more about our culture, follow us on Instagram @HubSpotLife.