We recently encountered a performance bug that served as a great reminder that even though the modern frontend best practices of the day add value to our applications, they are not silver bullets that can solve for every use case. Read more to learn about how our immutable-first approach resulted in an unfortunate performance degradation in our frontend - and the alternative that saved the day.
As engineers, we live in a world of trade-offs. We are constantly deciding between this approach or that approach, these technologies or those technologies, this style vs that style and so on and so forth. Many of these paradigms in JavaScript, like immutability, have become the de facto standard when building applications, lightening the cognitive load that can come with the work that we do. Coincidentally, this pattern of thinking might be creating blindspots in our decision making and subconsciously eliminating viable solutions before getting a chance to consider what trade-offs are best for our customers and/or the task at hand.
We recently encountered a performance bug that challenged this exact pattern of thinking as it relates to immutability in our frontend applications and reminded us that even though immutability provides many benefits, it is still a tool to be leveraged as we need it and not a silver bullet that solves for every use case.
Before diving into the problematic code related to this incident and the performance benchmarks collected, let’s refresh ourselves on a few key aspects of immutability and how it fits into JavaScript.
(Im)mutability in JavaScript
In JavaScript, the distinction between immutability and mutability is made between primitive types (such as numbers, strings, booleans, and symbols), and reference types (such as objects, arrays and functions). Primitive values are immutable, meaning once a primitive value is created it can’t be changed, although the variable holding the value is able to be reassigned. Take a look at the following example:

As you can see, we are defining a variable itemCount with a primitive value of 1. We are then reassigning a new value to the variable itemCount later in the program. The important distinction here is that we are reassigning the variable itemCount with a new primitive value, not modifying the original value.
However reference types are mutable, unlike their primitive counterpart, meaning their value can be modified without creating an entirely new value. Take a look at the code below:
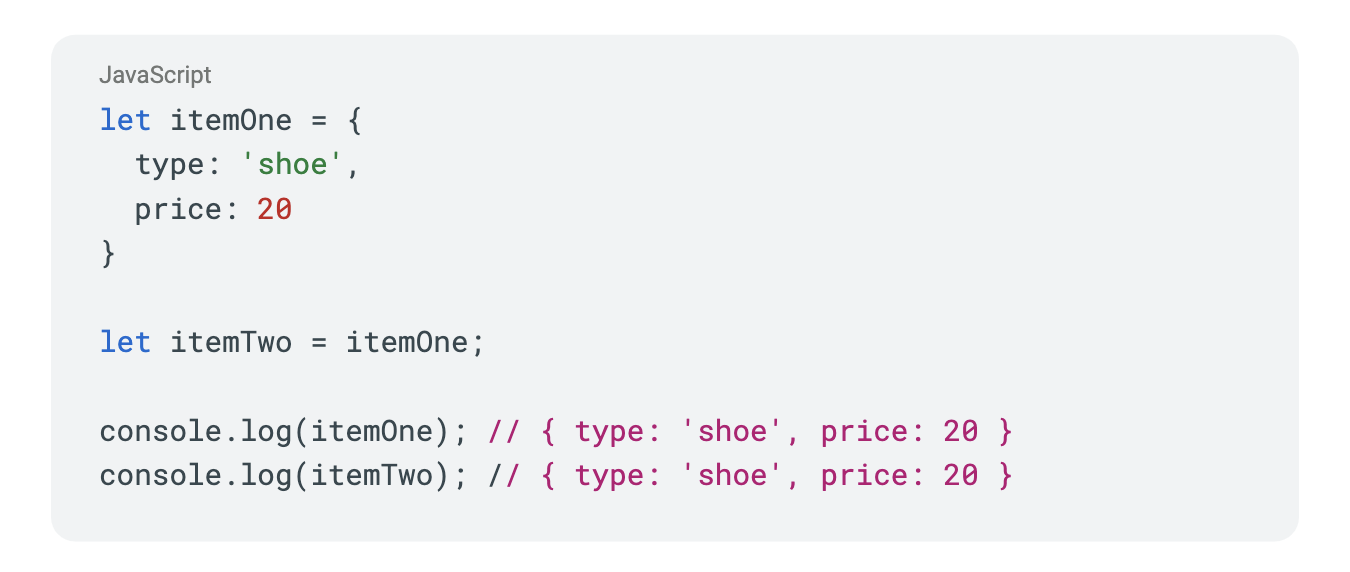
We define a new object itemOne with two properties then define another variable, itemTwo that is referencing itemOne for its value. If we change the price of itemTwo, you will notice that both objects' value of price update.

This might be unexpected at first if you are unfamiliar with these mutable and immutable rules in JavaScript, but essentially the values of itemOne and itemTwo change in this manner because reference types don’t actually hold a value, but rather point to an object’s location in memory. When one changes the other will as well, since they are both pointing to the same location in memory. Even in this simple example, you can see the potential risk of mutability in a real world application, which is why most modern frontend applications adhere to an immutable-first approach to help mitigate side effects like this throughout an application.
Even though the potential side effect(s) of mutability can be a legitimate deterrent in real world applications, one of the pros of mutability is that it can provide a great degree of flexibility when it comes to manipulating data. By being able to change the state of an object after it has been created, you can easily add, remove, or modify properties of the object. This makes it easier to dynamically generate and modify data within an application. On the other hand, this pattern can lead to unexpected side-effects, as seen above, if the object is not properly managed.
Immutability on the other hand, provides more safety, stability, and predictability of the data flowing throughout an application. By ensuring that an object can’t be changed after it has been created, you can guarantee that the data will remain consistent across the application, but it can also make it more difficult to perform complex operations.
How does immutability look in practice?
For our use case, we needed to have a function that converted an array to a map - think of an array of gates that inform us about what features a user has access to. The array was of varying sizes and the contents of the array were strings of varying lengths. To make this happen, we needed a solution that would iterate over each item in the array, apply each item to a map and return the new map with all the contents of the array. Keeping immutability in mind, let's take a look at the code below:

As you can see we were using Array.reduce to iterate over each item in the array, add it to a map and return the newly created map on each iteration. The key takeaway here as it relates to immutability, was that we were creating a new object on each iteration and using the spread operator to pass along the data from the previous instance of the object. If you have used reduce in the past, this likely looks familiar to you as this is a common way to utilize reduce with immutability in mind. Once it looked good to us, we merged the code in.
But then everything got SLOW...
This is where we noticed the performance issue mentioned at the beginning. After this code made its way to production, our customers began experiencing a large number of timeouts affecting key areas of the HubSpot application. Something about the above code was causing an issue - let’s dig into some benchmarks.
Disclaimer: The benchmarks presented below are derived from the average execution time over 10 runs for each group. Results will vary depending on overall dataset size and its values as well as the execution environment. Our test was performed in a node environment with an array of strings of random size with a minimum character length of 5.
Considering the immutable friendly usage of Array.reduce above, let’s take a look at the performance metrics we ran to figure out where we were going wrong.
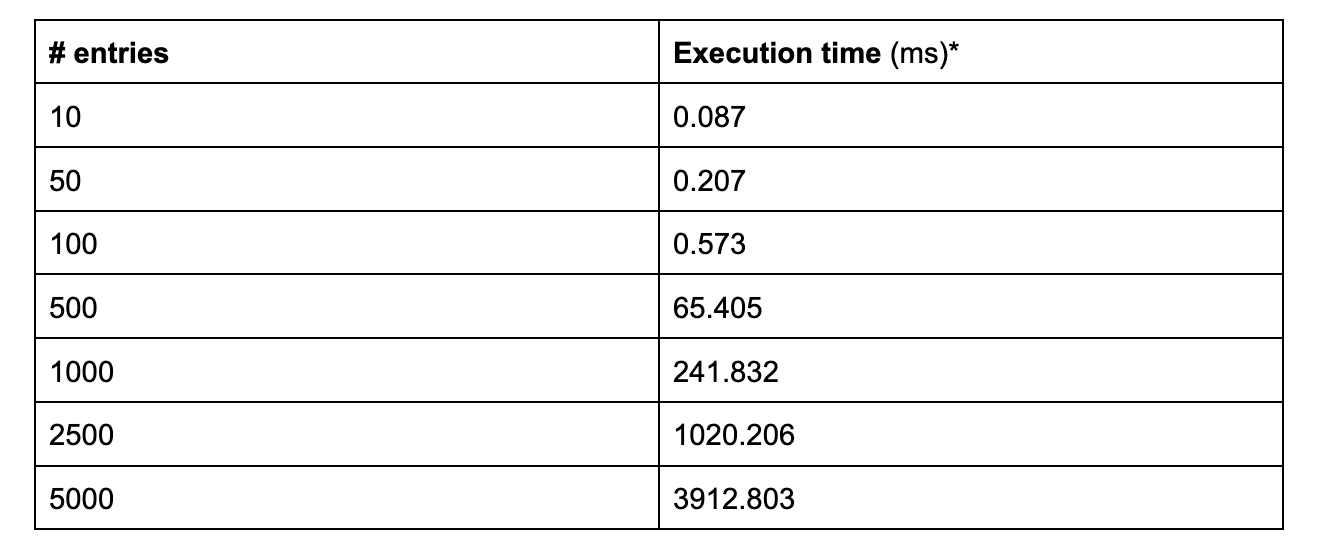
As our input workload grew (i.e. array of strings), the immutable Array.reduce method started experiencing noticeable performance degradation. How could this be? Even though this implementation of Array.reduce appears to be the "common approach", at scale the performance began to exponentially degrade resulting in timeouts within our application.
Mutating values saves the day
Continuing with our performance metrics, we adjusted our implementation to not be immutable, but instead mutate the initial object created on each iteration. As I mentioned earlier in the article, mutating data directly can be dangerous and should be handled with care. That being said, take a look at the code below:

Instead of creating a new object on each iteration and passing along the data from the previously created object, we mutated a single object and added new keys to it on each iteration. While this approach introduced mutability, it provided a certain level of readability over its immutable counterpart and as you will notice from the benchmarks below, it blew the first implementation out of the water.
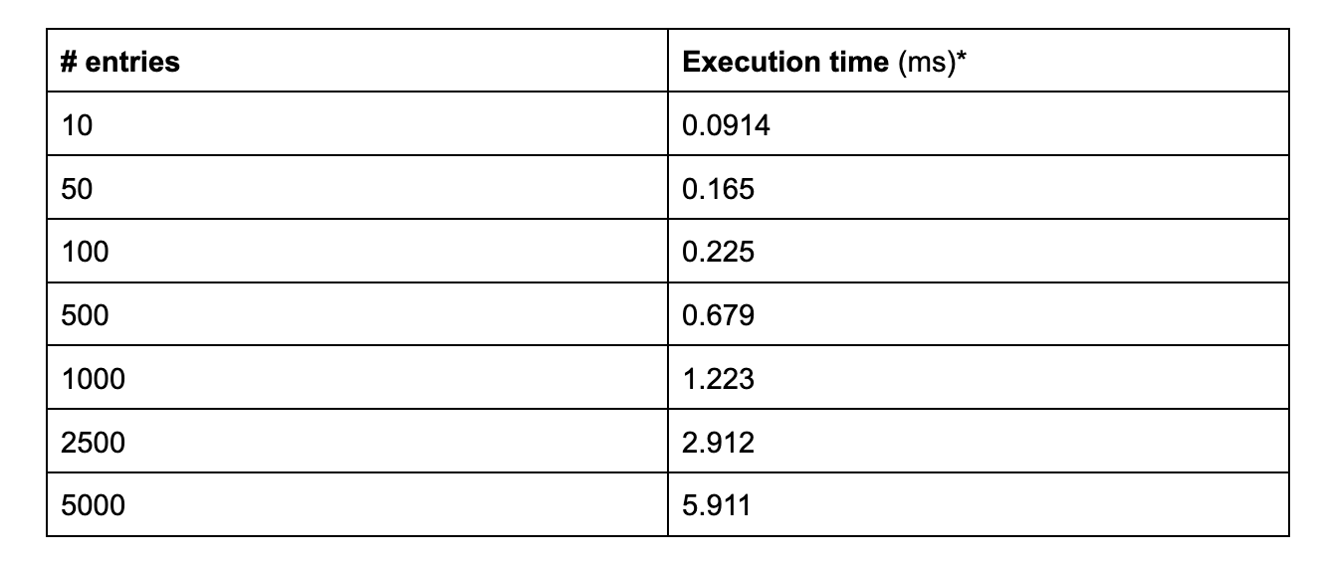
With the largest input for both our mutable and mutable instances of the reduce method, we experienced a ~3.5 second execution time improvement from the immutable approach to the mutable one.
To be clear, I am not proposing we throw immutability out the window based on this simplified benchmark comparison, as the benefits of immutability add immense value to an application as a whole. Rather I hope to remind us all that mutability can be a beneficial tool in our tool chest, if used properly. There is a good chance that mutating data directly isn’t the right solution for your application. That’s okay. Like we said before, immutability is often the safer solution. Thankfully, there are many other options out there to solve this type of problem that transcend the examples highlighted in this article.
Without providing an exhaustive list of solutions for this hypothetical scenario, I would like to shout out one common approach that honors immutability and outperforms the initial immutable reduce method for comparison sake.
Object.fromEntries takes in an iterable like an Array or Object and returns a new object. Take a look at the code below:

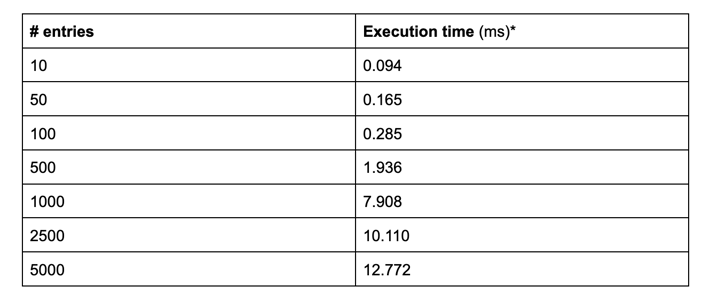
This is a quick and easy one-liner, and even though this is a tad slower than mutating the object directly in the reduce method, it still outperforms the immutable reduce approach. At the largest dataset, we see less than a hundredth of a second difference in performance - which is nothing to scoff at.
Using Array.reduce was the best solution for our use case but depending on your application needs, there are other options outside of swapping out the different built-in methods showcased above. For instance, if your application called for it, a viable option could be considering using a different data structure, like Set, which natively provides a performant way to eliminate duplicate data and includes handy built-in methods, like has, for easily and efficiently accessing data within the array-like structure.
Wrapping Up
At the end of the day, making decisions like mutability vs immutability or data structures greatly depend on your application, use case, and scale. I hope that our performance issue and related benchmarks in this article provided a great reminder that programming paradigms should be carefully considered and not blindly followed in hopes they shield us from engineering decisions, errors or negative outcomes. It is our job to evaluate a problem and assess the tradeoffs in pursuit of the best outcome for our customers.
Interested in working on challenging projects like this? Check out our Careers Page for your next opportunity! And for a behind-the-scenes look at our culture, visit our Careers Blog or follow us on Instagram @HubSpotLife.