How Twitter and HubSpot Are Scaling Build Systems
Tech Talk at Night is a chance for engineers to get together and talk about the problems they're solving across the stack. We hosted the second ...
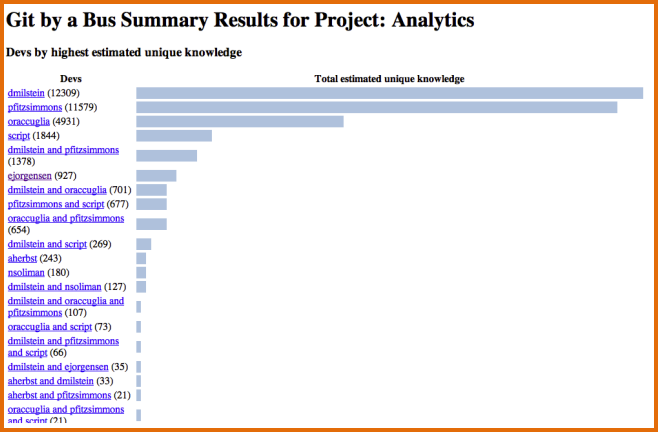
Developers are always being told to document and collaborate on their code in case they are "hit by a bus." Usually "hit by a bus" is code for "go to another company," but the point is the same: if you are a developer with unique knowledge of code, that knowledge is at risk if you depart either your job or this life.
I got interested in the problem of identifying and quantifying that risk, and Git by a Bus is the result. It analyzes the history of your git repository (there is also experimental svn support), estimates unique knowledge per file per developer or group of developers, and then writes an html summary of unique, at-risk, and orphaned knowledge for each project and file in your repository.
If you're interested in trying it out or hacking on the code, HubSpot has let me open the source, which is available on github here. Read on for more details on how it works.
I experimented with a few different models for unique knowledge as I was writing the script, but the one I settled on is pretty simple and has the virtue of allowing you to estimate risk with the joint probabilities of more than one developer being hit by a bus.
In the final model, the "knowledge" contained in a file at any point in time is represented as the number of lines in the file plus an adjusted "churn" value. "Churn" is the number of lines that are estimated to be changed rather than added in a revision, and we multiply by a constant (by default 0.1) to translate that churn into a knowledge value. In other words, we estimate that for every line added to the file, one knowledge point is added, for every line removed, one knowledge point is removed, and for every ten lines changed, one knowledge point is added.
Using this model, Git by a Bus marches chronologically through the log of each file in your repository, applying the following algorithm for each revision:
At the end of this process, we have basically built up a venn diagram of how all the knowledge in the file is distributed. For example, if three devs A, B, and C had participated in a file's history, the output of our algorithm would show how much knowledge each dev held uniquely, how much A and B held jointly, or A and C, or B and C, and how much estimated knowledge was shared between all three.
Now, using supplied input files that tell us which devs have already departed, and the estimated risk of each remaining dev getting hit by a bus in some time frame, we can calculate:
