The Fault in Our JARs: Why We Stopped Building Fat JARs
HubSpot’s backend services are almost all written in Java. We have over 1,000 microservices constantly being built and deployed. When it comes time ...
Part of my job at HubSpot is to meet and welcome new potential HubSpot engineering hires. One of the most surprising things I get to tell them is that we deploy 200-300 times a day.
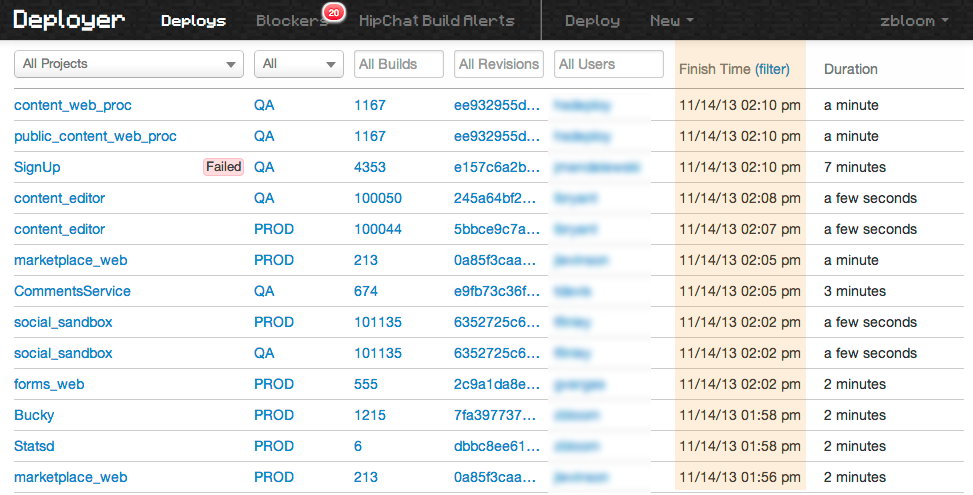
Let's look at what makes that possible:
As we grow, we do it by letting our teams focus on smaller chunks of the product (and by having more product), not by throwing more people at the same problems. No matter how much we grow, there is always a single team of three or four developers who own and are deploying any part of the product. Through this, we have avoided having to create numerous staging environments. Most importantly, each of our projects can be ran locally and deployed individually.
One reason a team might not be able to move towards smaller projects is a need to share code. We work around this by creating common libraries to nurture shared utilities. One lesson we've learned is the danger of allowing these libraries to become collection points for every random bit of code a developer wants to hang on to. In what we build now we are very careful to make each project do a single thing in a way that can be easily understood and documented. Our open-source projects are good examples of this philosophy.

When a commit gets made to master, a build kicks off in Jenkins. When the build is done, a developer can send it to qa or prod from the terminal, or the web UI. For most of our frontend projects a 'deploy' just means bumping a static pointer on our CDN, and only takes a few seconds. It stands to reason that you can't deploy a lot if each deploy isn't fast and easy.
For backend projects this is accomplished by a fabric task connecting to each server hosting that application, and to each load balancer that application is behind. The build is pulled down from S3 and spun up on it's own port using monit. Once the new process has passed a health check, the port numbers are swapped in the load balancer, and the old processes are killed.
All of our builds live forever as tarballs on S3. So we can deploy any build at any time, or rollback to a previous build at any time. Having our deploy system fully standardized lets anyone do a rollback, even someone not familiar with the project in question if need be.
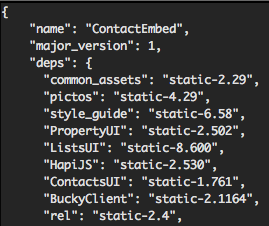
When a build runs it locks in the versions of every dependency. This means that if that build is deployed today, or in a year, it will still point to the correct dependencies. Our static build system gives us the ability to lock our projects into specific dependency versions, similar to npm. With locked versions, we can upgrade libraries and change projects without fear that downstream projects will break. All of our services communicate over versioned APIs, allowing different versions to coexist simultaneously.
This also means that a part of the app can only change when it itself is deployed; other projects getting changed or deployed won't have any effect. With this we can ensure that a project can only break when a member of the team that maintains it is at their keyboard.
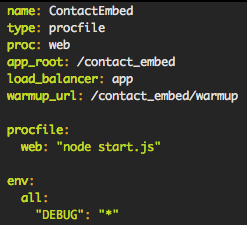
Taking a page out of Heroku's playbook, we have adopted a Procfile based deploy system. What this means is that every type of project has a set of files which explain how they are built and ran. Our deploy system only needs to know what it should run, what environment variables it should set, and how to make sure it's working. Beyond that, everything is generic.
This means that any service can be deployed to any of our EC2 instances at any time. We can deploy Java, Node.js, even Go. It also makes debugging easier: Every machine is configured with one of a handful of configurations, every process logs to the same places, is restarted the same way and is deployed the same way.
We try to extend the idea that each project should build it's own environment as far as we can. With Node, for example, we use nvm to allow each project to define its own Node version and package the binary with the built files. While we do use puppet for machine-level config, only a handful of people have to touch puppet config files day-to-day.
Fucking Ship It Already: Just Not to Everyone At Once - http://t.co/h1273a2RpM #shipit
— David Cancel (@dcancel) October 28, 2013
That quote is courtesy of David Cancel, our former Chief Product Officer, and it accurately describes our attitude towards getting code to production (including the profanity). Every minute code lives in a branch, it is aging and dying. We do everything we can to get it onto master and into the product as quickly as we can.
One tool is the 'gate'. A gate is a switch we can turn on or off for a specific set of customers. Gates let us test new features or changes on our internal account, then with a subset of users, before rolling it out sitewide. Features can live behind gates for months while we work through feedback and make revisions, or just for a few hours while we send out notifications to the team.
One of the biggest issues we've faced as a B2B company moving quickly is learning how to effectively communicate with our customers about changes.
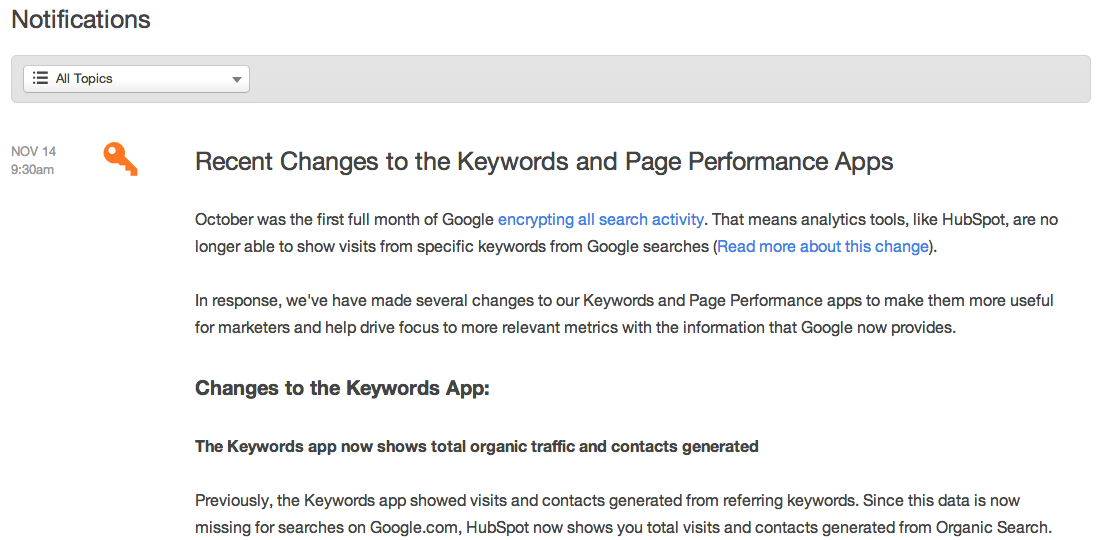
For us this means posting big changes to a notifications page, adding a notifications bug to our nav bar, and sending emails with these changes to the HubSpot team so we could all be on the same page. We also had to learn how to communicate these changes and time releases such that people could have enough warning to make them comfortable.
We also learned to give people time to make big changes. When we reengineer a big part of the app, we do everything we can to allow people to switch in their own time.
As I've said we deploy 300 times a day, but we only have 85 engineers. This means that any given engineer is pushing the deploy button four times a day. Without some amount of automated testing, each engineer would spend the bulk of his or her day just clicking links and making sure he or she didn't break anything.
We try to cover critical libraries well with unit-level tools like Jasmine, as no one wants a library change to break half the site (although, nothing can break if it itself is not deployed). One thing we don't do is TDD. We write Selenium-style tests after things have broken the first or second time and we want to make sure it never happens again. If an issue does occur, we can fix it in another deploy in just a few minutes. This ability to correct mistakes quickly means we can tolerate small bugs and issues which are only around long enough to effect a tiny group of customers. This leaves our testing more focused around preventing whole apps or systems from being taken down.
HubSpot engineers open an average of 78 Github pull requests a day. Although using them is not required or enforced, they are critical in catching errors and misunderstandings before they make it to production. Some PRs get merged immediately by the engineer who opened them, others can accumulate dozens of comments and edits before being merged. The general practice is to @-mention interested engineers on your team and any other team which might be effected by the change. Those mentioned will reply with comments, or just a quick  .
.

If a commit includes a ticket id, it is associated with that JIRA ticket. When that commit gets deployed, the ticket is automatically updated. This allows engineers to close tickets when an issue gets fixed without having to wait for the full deploy process to finish. It also keeps stakeholders informed so they don't have to wonder when their change will really show up.
Deploys also post HipChat messages in the relevant team's room, helping team members to figure out what's up if an issue appears.

Every company goes through an evolution in how it manages configuration information. First it's inline with code, then in dedicated config files, and eventually, in a distributed system. We use a webapp on top of ZooKeeper to synchronize the 2500 configuration bits and pieces and distribute them to our 1500 EC2 instances. Configuration values can be updated and distributed to our whole network in about sixty seconds, allowing config to be changed on running instances without redeploying.
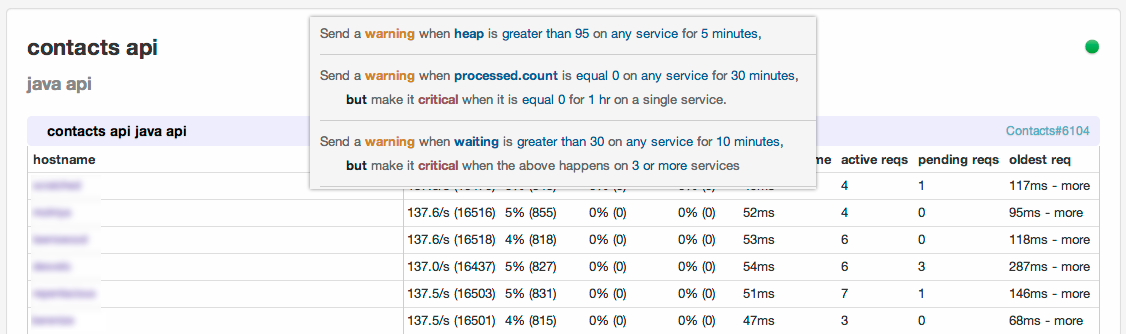
We have an internal tool called Rodan which gathers metrics from all of our services. Based on rules, the service can alert us with PagerDuty when something goes wrong. The balance between under and over alerting is something we've had to learn over time. It is very easy for engineers to get alert-fatigue and begin to ignore critical notifications. One thing we've done is to only allow our QA systems to alert during working hours, to ensure that non-critical systems aren't waking up anyone in the middle of the night.
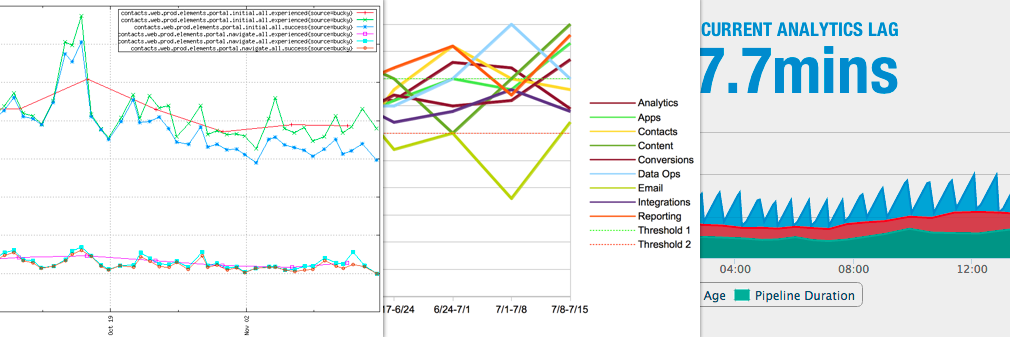
One of the first things we did when it came time to improve our reliability is figure out what metrics we could track to let us know if we're moving in the right direction. We built tools like Bucky, and adopted ones like OpenTSDB. We use this data to ensure both that individual changes don't cause performance or reliability issues, and that we are improving in the long-term.
With Bucky we track timing data from every page load and API request, as experienced by our users. We also get a Sentry alert if any part of our app fails to render certain elements in a reasonable amount of time using an internal tool called Reagan. Once we have that alert, we can use another tool called Waterfall to track the request all the way down to our databases.

One theme you'll notice is that we try not to operate with hard-and-fast rules or process. We leave it to the individual engineers to decide how much PR review, how much testing, and how much waiting they need to do. We can provide metrics, tools, advice and experience, but at the end of the day, it's the individual engineer's responsibility to build quality software. This model works if you only hire smart people you trust, and if you can take the occasional screw up in stride.