At HubSpot, we recently did the work to launch our largest data store on Amazon Web Services’ new Graviton servers. It took time to get that data store, HBase, to work on Graviton servers, but the performance and cost benefits were worthwhile. Read on to learn about how we did it.
Amazon Web Services has historically offered all of their Elastic Compute Cloud server types in a single CPU architecture, known variously as amd64, x86_64, x86, “Intel”, etc. This is the architecture that’s inside almost every Windows computer in the world, and until recently every Mac. It’s the architecture that all HubSpot servers ran on until recently. Starting in 2018, AWS began offering some server types that have a different CPU architecture, known variously as ARM, arm64, ARMv8, etc, and that Amazon has branded as Graviton. This is also, more or less, the architecture that’s inside every iPhone, and in newer Macs.
Amazon’s pitch with their Graviton servers is that while each server individually may not be the most powerful in every aspect, they offer more performance per dollar. Additionally, they claim the servers are up to 60% more energy efficient, although this has not been independently verified. For customers like HubSpot who run many servers, this is an attractive offer. However, to take advantage of it, we would need to rebuild large amounts of our software to enable compatibility with multiple architectures.
Building
Java bytecode can run on any platform with a working Java Virtual Machine. Since there’s already an arm64 JVM, we can generally run existing builds of our Java code on Graviton servers without modification. We’re doing this successfully for many applications at HubSpot today, with no intervention necessary from the application owners. For data stores like HBase, more work was required at the time.
HubSpot's approach to targeting different architectures at build time is to run the build in the target architecture, and therefore not need to handle the complexity of cross-compiling for one architecture from another. However, when executing a single build process, that build can only take place on one machine. Our primary solution to this dilemma was to run the meat of the build process inside Docker containers, and use Docker's support for CPU emulation to make the container believe it's on a different architecture than it really is. Code running in an emulated container is much slower than usual, but this technique is otherwise very effective, and it allows you to drop build artifacts for multiple architectures in the same directory, allowing them to then be packaged together. Some of the things we build are Docker images themselves, which naturally build in a containerized way, and when building Docker images, it's necessary to publish both architecture flavors of a single Docker image at once.
Pieces of the build stack used to build HBase hadn’t even been built for arm64 yet themselves. Of note was the protobuf 2.5.0 compiler and native library, which did not rebuild easily. A few functions in the protobuf codebase had multiple, architecture-specific implementations, but none of them were for arm64. This version of protobuf predated the popularity of the arm64 architecture. We created a patch for the protobuf code that adds generic, multi-architecture support for the necessary functions. We decided not to contribute this patch back to the protobuf project, because equivalent support is already in later versions of protobuf.
HBase is built on Hadoop, which is mostly written in Java, but also has pieces written in C. As a result, we needed to make Hadoop's build process support multiple architectures. This build is large, and would take an hour if run in an emulated Docker container. Luckily, because the outcome of the build is a separate RPM for each architecture, it's possible to run the build for each architecture completely separately, and therefore on different machines. We’ve set up our build configuration to run the build script concurrently on machines of each architecture.
HBase itself does not directly contain any native code, and therefore can immediately run on any CPU architecture. Our HBase build process marked the resulting RPMs as compatible only with x86_64, so by changing the RPM metadata to note that its contained code would work on any architecture ("noarch" in RPM vocabulary), we immediately got copies of HBase that would work on arm64.
One particular package that we installed on our HBase servers was not simple to re-compile. Most of our HBase data files are compressed using the Lempel–Ziv–Oberhumer compression algorithm. There's a native library liblzo you can easily install from public repos that implements this core algorithm, but then unfortunately we also need another native library that adds Hadoop-specific extensions to this. We had been using a single RPM to provide this library, for which no working build process existed. Since that RPM wouldn't work on arm64, it was time to finally start reliably building this library again. This had the added bonus of giving us the opportunity to improve how this library was integrated into our dependency tree, so now all builds of this library for all architectures and binary formats (Linux's ELF and Mac's Mach-O) are packaged into a single JAR. That JAR is then distributed as both a noarch RPM and a Maven package.
Testing
With everything rebuilt, it was possible to start up some or all of the nodes in an HBase cluster on arm64 servers. We run our NameNodes, JournalNodes, and HMasters in Kubernetes pods. We can apply an annotation to tell Kubernetes that our pod can run on both architectures. Kubernetes will select the flavor of your Docker image that matches the architecture of the chosen Node automatically. Our RegionServers, however, are dedicated EC2 servers. It's important for HBase's performance that RegionServers write their data files to machine-local SSD volumes. There are two Graviton instance classes with this storage: is4gen and im4gn. Unfortunately, both were relatively underpowered in terms of RAM compared to the other instance classes we use. For example, is4gen.2xlarge has 48 GiB of RAM, while i3, i3en, and i4i at the same size all have about 64 GiB. HBase uses a lot of RAM for caching, so this is a significant limitation. Because is4gen has more memory than im4gn, we focused our testing on that type.
HubSpot’s HBase team has a few testing harnesses that we can use to send identical synthetic load to two clusters to compare how they perform. We found that as long as memory was not a constraint in a cluster's workload, is4gen was considerably faster than the i3en instance class, its closest x86 counterpart. This is in line with Amazon’s public statements.
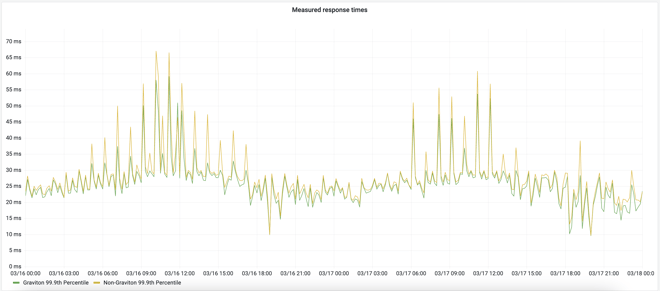
After testing on synthetic load, we also tested with live load using our shadow reads system. Our HBase client library has the ability to send a copy of every read request intended for a given cluster also to a configured "shadow cluster." We set up shadows for two clusters in our North America region, replicated all the data into the shadows, and then enabled shadow reads for them. This showed that, at least for reads only, request latency at the 99.9th percentile was about 2x improved on is4gen, with diminishing returns further down the scale.
Rollout
HBase wants to keep metadata about each data block in memory, including bloom filters that track every row. If these cannot all fit in memory, performance degrades considerably because multiple sequential disk reads are required to service a query. We have metrics on the size of these data structures, so we can assess whether changes in the number or shape of RegionServers will cause them to spill onto disk. Clusters with relatively small bloom filters and large block sizes are likely to work well after conversion to is4gen.
With this in mind, and good results so far, we were comfortable using is4gen for real production workloads. We chose to convert a cluster to is4gen that has lots of data at rest, but a small request volume. At press time, that cluster’s RegionServers are now about half is4gen servers, with the remainder i3en. This cluster's workload is write-heavy, and we are already seeing a noticeable improvement in 99.9th percentile latency of those writes. This will directly affect our customers’ experiences by making some of their page loads faster.
Next Steps
Soon, the HBase team will augment our "tuning rules" system to automatically identify candidate clusters for conversion to is4gen. Unfortunately, our tuning rules system is tightly coupled with proprietary elements of the HubSpot stack, so we cannot share this code. There have not been any significant HBase outages or breakages caused so far by the usage of Graviton servers, and the performance and cost benefits are great.
Interested in working on challenging projects like this? Check out our Careers Page for your next opportunity! And for a behind-the-scenes look at our culture, visit our Careers Blog or follow us on Instagram @HubSpotLife.