So you want to be a User Researcher? Advice from HubSpot’s UX Research Team
UX Research seems to be one of those careers: everybody in it is a life-long learner. It’s a great fit for the naturally curious, and for people with ...
What's the best way to organize the information in your company's main website menu?
One of the gold standard approaches for tackling questions about navigation design, or information architecture (IA) more generally, is to run a card-sorting study. I won't dive into the particulars of how to run these kinds of studies, but I will note that card sorting is a well established, versatile methodology with a variety of applications for IA research. Card sorts are powerful enough to provide researchers with valuable insights into users' mental models, but uncomplicated enough that they can be run with nothing more than some paper and a pencil.
The card sorting methodology has its roots in experimental psychology. Many cognitive scientists (including me!) are interested in understanding how the information in our minds is structured and organized. As early as Plato (~320 BC), scholars have assumed that categories and taxonomies play an important role in terms of how our knowledge is structured, and card-sort experiments have become a standard approach for exploring questions in this domain because they provide evidence of our categorical thinking.
For example, 50 years ago, the psychologists Battig and Montague (1969) gave hundreds of research participants the name of a category like FURNITURE and asked them to list as many items belonging to the category as possible in 90 seconds. They found that about 90% of people will include Chair in their list, but only about 15% will include Lamp, suggesting that lamps are probably only loosely related to this category in our minds, while chairs are prototypical exemplars.
I'll get back to why this matters shortly, but the point is that, as humans, we're really good at categorizing the information we encounter, and card sorting capitalizes on this fact.
 While IA research is usually focused more narrowly on understanding how a specific user group organizes information from a specific website, practitioners are still dealing in the currency of categorization. This is conveyed quite clearly in the title of Spencer's (2009) classic UX reference, Card Sorting: Designing Usable Categories.
While IA research is usually focused more narrowly on understanding how a specific user group organizes information from a specific website, practitioners are still dealing in the currency of categorization. This is conveyed quite clearly in the title of Spencer's (2009) classic UX reference, Card Sorting: Designing Usable Categories.
All things considered, card-sorting is great way to learn about your navigation structure, which will almost always end up incorporating some form of categorization. Yet I believe there are some limitations to this approach that all researchers— especially those at SaaS companies—should take into account.
To illustrate: Imagine being an information architect or researcher at an online furniture retailer like Wayfair. Given what we already know about people's opinions about the category FURNITURE, we might predict the results of a card sort with some degree of accuracy. If we look at Wayfair's website, we would in fact find that 8 of the top 10 items given by Battig and Montague's participants do appear under the Furniture tab.
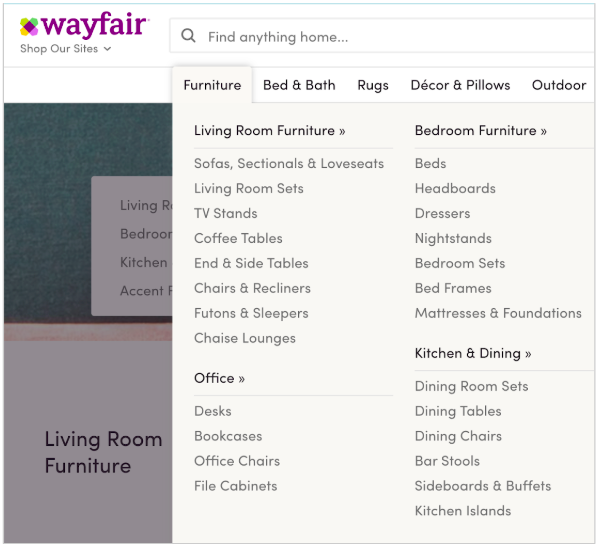
What's missing? Lamp and Television. Recall that Lamp is the last item in the researchers' list (and presumably a weak fit in the FURNITURE category). This item was put into a separate Lighting tab on Wayfair's website, which I think is a good UX call. And considering what televisions looked like 50 years ago, we might understand why they made it onto the original list, but why they're excluded in Wayfair's Furniture tab.
Nearly all of Battig & Montague's (1969) top FURNITURE responses are listed under the Furniture tab on Wayfair's website.
Now, imagine that you're doing IA research for a SaaS company like HubSpot, which offers its customers nearly a hundred different tools designed to help small and medium-sized business grow. Just as the needs of business are diverse and wide ranging, so is the set of tools our users require to do great work. Here, some of the limitations of card-sorting studies become clear.
For one thing, categorization tasks are affected by the amount of variability in the set of things to be organized. We can probably get people to agree that tables and desks are more alike than are tables and lamps, but if we look across the set of all potential items in a FURNITURE category as a whole, we can see that there's a fair degree of uniformity.
In contrast, we don't expect there to be a lot of uniformity in function or purpose between an email editor, an SEO tool, and a sales report, and our research finds that participants tend to need many different groups to contain all of HubSpot's offerings. Variability makes sorting more difficult, and SaaS companies often provide tools or features that are very different from each other.
There's also the issue of arbitrariness, which corresponds to how "natural" the categories are. This may be determined by our past experiences with a category, our impression of how cohesive the set of members is, or even how informative the category label is. Despite being a highly subjective construct, we know that people do have converging expectations about a category like FURNITURE, which implies that it is a rather natural category in people's minds. For business software, however, we can be reasonably sure that we'll end up with some categories that are more arbitrary than natural. After all, SaaS companies are often inventing the categories and the items they contain in real time.
There are two points about task sensitivity that warrant mentioning. Although they're related, they refer to two different kinds of tasks.
Card-sorter's task. Scientists don't agree entirely on what people are analyzing when they're creating categories, but one line of thinking is that we look for commonality among to-be-grouped items on the basis of their shared features (e.g., for FURNITURE, is made of wood, has legs, etc.). Sorting studies usually instruct people to create categories that make sense to them, and I would argue that this engages our default tendency to create groups based on similarity. This is not always a bad thing—especially not if you're selling furniture. But similarity represents only one way in which information can be related, and it may not always be the optimal relationship to highlight in your IA.
Navigator's task. There's also a related concern that categories work well when your users need to act on categorized data, but they work less well when your users need something else: On average, a Wayfair customer probably visits the company's website looking to purchase a product, like a chair, and arguably, they expect to find an organized taxonomy of furniture items to help them track down the exact chair they want.
In contrast, a HubSpot customer might come to product with the goal of contacting a sales lead, writing an informative blog post, or setting up a chatbot for automating customer support interactions. In these cases, an optimal navigation experience through HubSpot is tied critically to context, and might be based on complex workflows. Card-sorting data is not necessarily well equipped to capture these nuances.
While research from psychology has left a permanent mark on the UX industry in the form of card-sorting studies, there's been surprisingly little recognition of another line of research that I believe has the potential to provide researchers with useful data about users' mental models: word-to-word association (or simply, association).
For the past 40 years, cognitive scientists have also explored questions about the structure of conceptual knowledge in terms of associations as a complement or alternative to categories. Rather than explain what association is, I'll demonstrate by showing how the research works.
I'll give you a word prompt, and then you take a few seconds to write down the first five words that come to mind.
Ready? Here's the prompt:
BEE
Did you come up with a list? If so, then read on...
The psychologists Nelson, McEvoy, and Schreiber (1998) conducted a similar task with hundreds of participants more than 20 years ago and determined that the most probable responses to this prompt are, in order: sting > honey > hive > insect > wasp. That is, these five words are taken to be the most common associates of the word bee. Because associations can differ from person to person, you may not have the same five items in your list. However, if we asked 100 people to create a list, we can be reasonably confident that these items will still be the most frequent to appear.
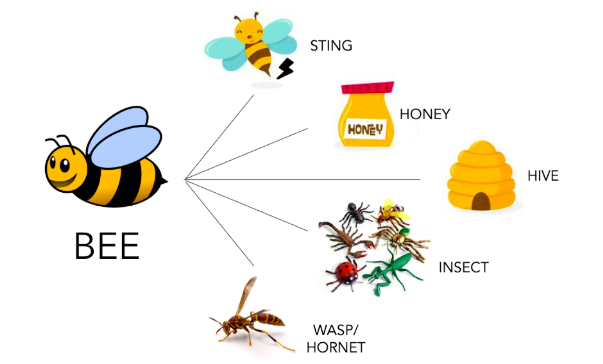
Clockwise from the top, these are the most frequent responses given to the prompt BEE in Nelson, McEvoy & Schreiber's (1998) well-known study.
What's important to notice here is that we've generated a list of associates that reflect a variety of different relationships between the items in the set, only one of which is based on similarity (wasps are similar to bees), and one that calls out the bee's category specifically (insect). So while associative relationships may be categorical relationships, they need only reflect patterns of co-occurrence in the participant's mind. What I care about as an IA researcher is that these patterns often reflect meaningful information: Bees sting, they make honey, and they live in hives.
Moreover, the differences between association and categorization are not merely theoretical. Rather, scores of studies have shown that, on cognitive or language-based tasks, things like processing efficiency can vary as a function of whether people interact with associated information versus categorized information. I'm not suggesting these findings would predict measurable differences in how users engage with site navigation when menu items are organized associatively versus categorically, but I do think the data suggests the need for careful consideration.
I believe the association studies can help IA research in at least two important ways: First, they can provide evidence of non-categorical relationships between candidate navigation items that might be missed in a card-sort study. At a minimum, such insights can provide researchers more information about users' mental models. Second, they can provide additional validation for groupings that might emerge in card-sorting data, indicating potential alternatives for splitting the data in a way that more closely matches users' expectations.
Here at HubSpot, we're looking at how to incorporate association research into our IA research program. In doing so, we're heading into uncharted UX territory, and we expect we'll have to update our thinking accordingly. As we refine the methodology and collect some instructive data, we'll be sure to share our findings here again.
Readers are encouraged to review Nelson and colleagues' original research to learn the finer points of how to conduct an association study (which, like card-sorting, is simple and can be done with just a pencil and paper) and of how to compute association strength between words (which requires little more than addition and division). And as always, check back with us for updates.
References
Battig, W.F. and Montague, W.E. (1969) "Category Norms for Verbal Items in 56 Categories: Replication and Extension of Connecticut Category Norms." Journal of Experimental Monograph, 80, 1-46.
Nelson, D. L., McEvoy, C. L., & Schreiber, T. A. (2004). "The University of South Florida free association, rhyme, and word fragment norms." Behavior Research Methods, Instruments, & Computers, 36(3), 402-407.
Penta, D. (2019) Reflections on Card Sorting for SaaS Navigation Research. Invited talk, Emerge Event Series #1: UX Research Team Building & Tactics: Wayfair Headquarters, Boston, MA. Oct. 8. https://emergeseries.splashthat.com/